인증과 인가의 차이
- 인증(Authentication) : 해당 유저가 실제 유저인지 인증하는 개념. 스마트폰에 지문인식, 이용하는 사이트에 로그인 등과 같이, 실제 그 유저가 맞는지를 확인하는 절차를 의미한다. 일반적으로 웹 어플리케이션은 아래 설명할 두가지 방법을 통해서 인증을 처리한다.
- 인가(Authorization) : 해당 유저가 특정 리소스에 접근이 가능한지 허가를 확인하는 개념. 예를들어 관리자 페이지-관리자 권한 같은 것들이 해당된다.
웹 어플리케이션 인증의 특수성
- 일반적으로 서버-클라이언트 구조로 되어있고, 실제로 이 두가지 요소는 아주 멀리 떨어져 있다.
- 그리고 Http 라는 프로토콜을 이용하여 통신하는데, 그 통신은 비연결성(Connectionless) 무상태(Stateless)로 이루어진다.
- 보통 모바일/웹 서비스의 인증은 HTTP 메세지의 헤더에 인증 수단을 넣어 요청을 보낸다.
비연결성(Connectionless) 무상태(Stateless) 의미 ↓
더보기
비연결성(Connectionless)은 서버와 클라이언트가 연결되어 있지 않다는 것. 채팅이나 게임 같은 것들을 하지 않는 이상 서버와 클라이언트는 실제로 연결되어 있지 않다. 그 이유는 리소스를 절약하기 위해서 인데, 만약 서버와 클라이언트가 실제로 계속 연결되어있다면 클라이언트는 그렇다고 쳐도, 서버의 비용이 기하급수적으로 늘어나기 때문. 그래서 서버는 실제로 하나의 요청에 하나의 응답을 내버리고 연결을 끊어버리고있다 라고 생각하면 된다.
무상태(Stateless)는 서버가 클라이언트의 상태를 저장하지 않는다는 것. 기존의 상태를 저장하는 것들도 마찬가지로 서버의 비용과 부담을 증가시키는 것 이기 때문에 기존의 상태가 없다고 가정하는 프로토콜을 이용해 구현되어 있다. 실제로 서버는 클라이언트가 직전에, 혹은 그 전에 어떠한 요청을 보냈는지 관심도 없고 전혀 알지 못한다.
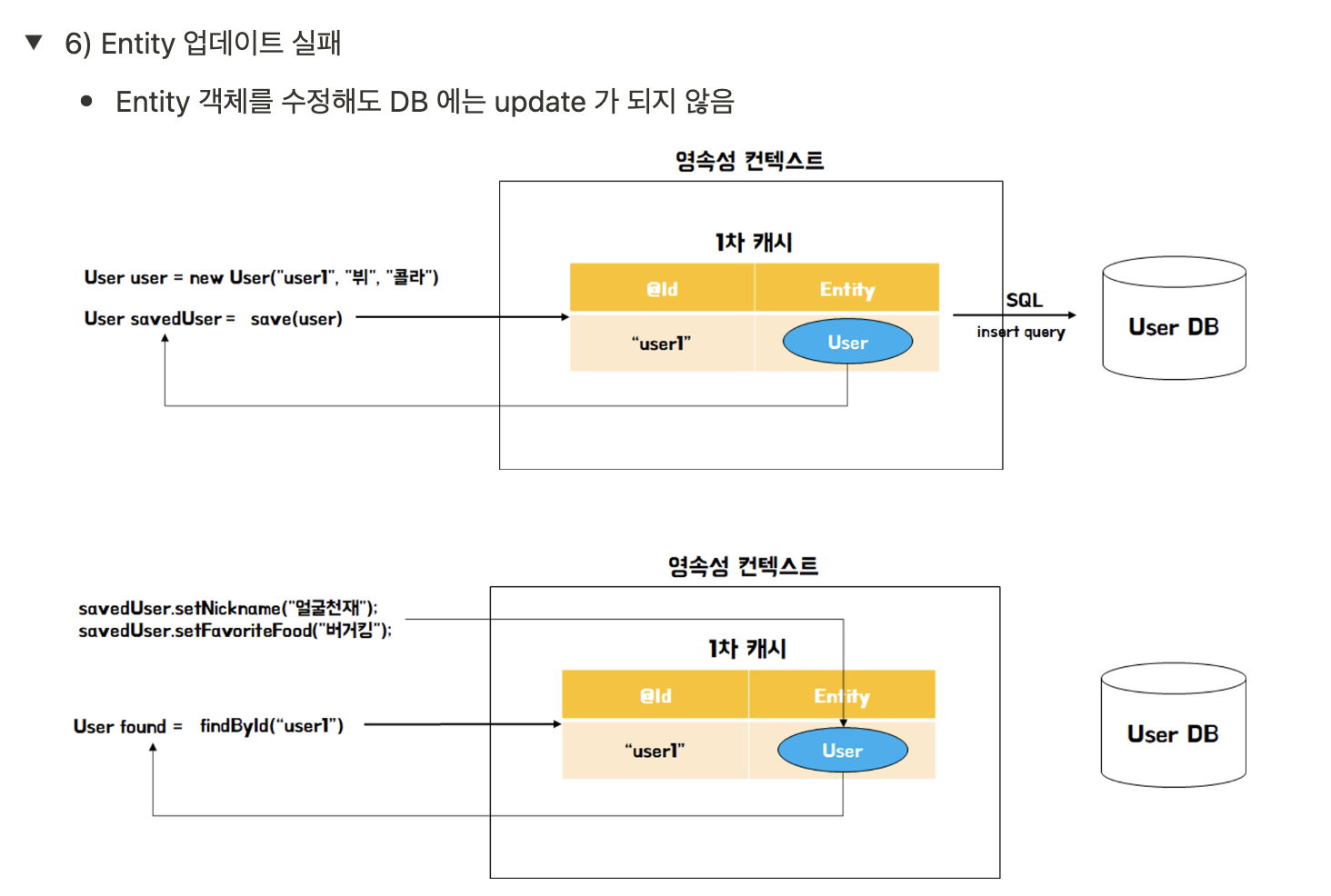
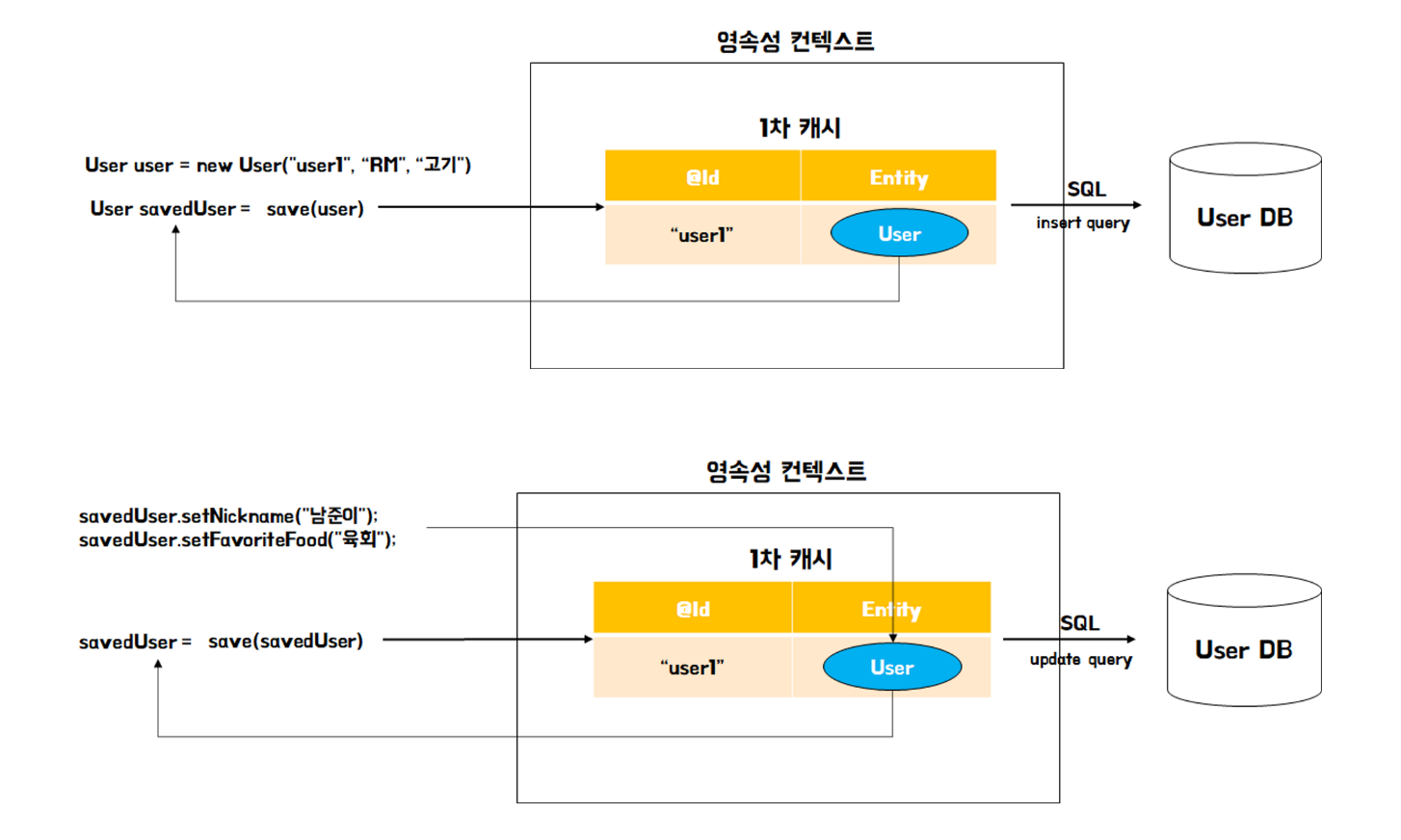
인증방식 (1) 쿠키 - 세션 방식
- 쿠키-세션 방식은 서버가 특정 유저가 로그인 되었다는 상태를 저장하는 방식
- 세션은 서버에서 가지고 있는 정보이며 쿠키는 사용자에게 발급된 세션을 열기 위한 열쇠(SESSION ID)를 의미
- 인증과 관련된 아주 약간의 정보만 서버가 가지고 있게 되고 유저의 이전 상태의 전부는 아니더라도 인증과 관련된 최소한의 정보는 저장해서 로그인을 유지시킨다는 개념
- 결과적으로 Session/Cookie 인증 방식을 사용하는 이유는 서버에 인증의 책임을 전가하는 것이다.
-
더보기
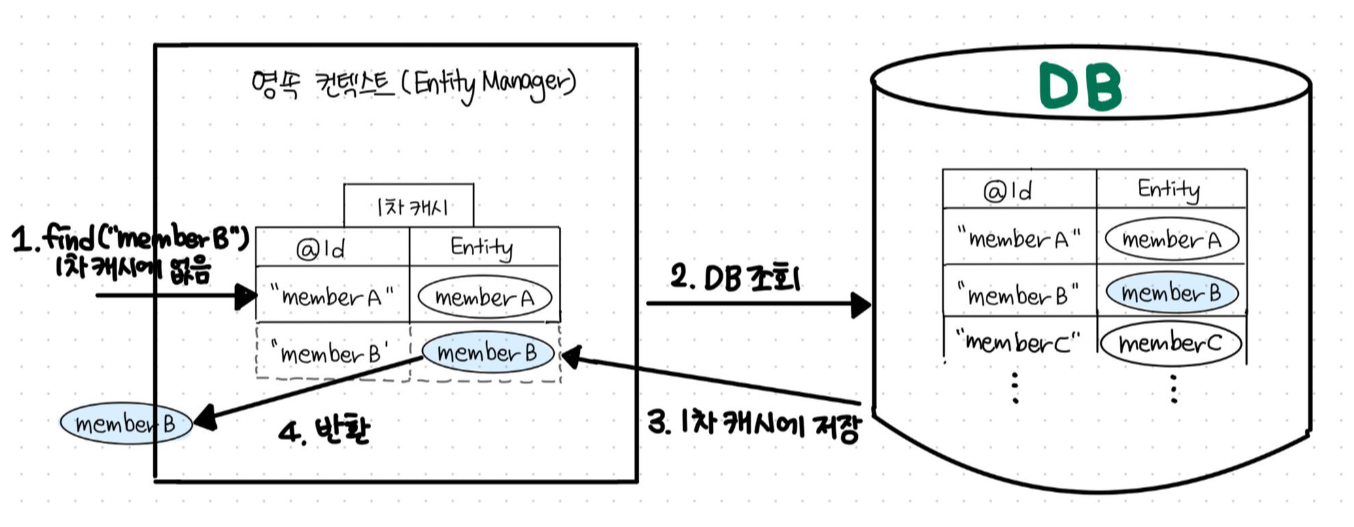
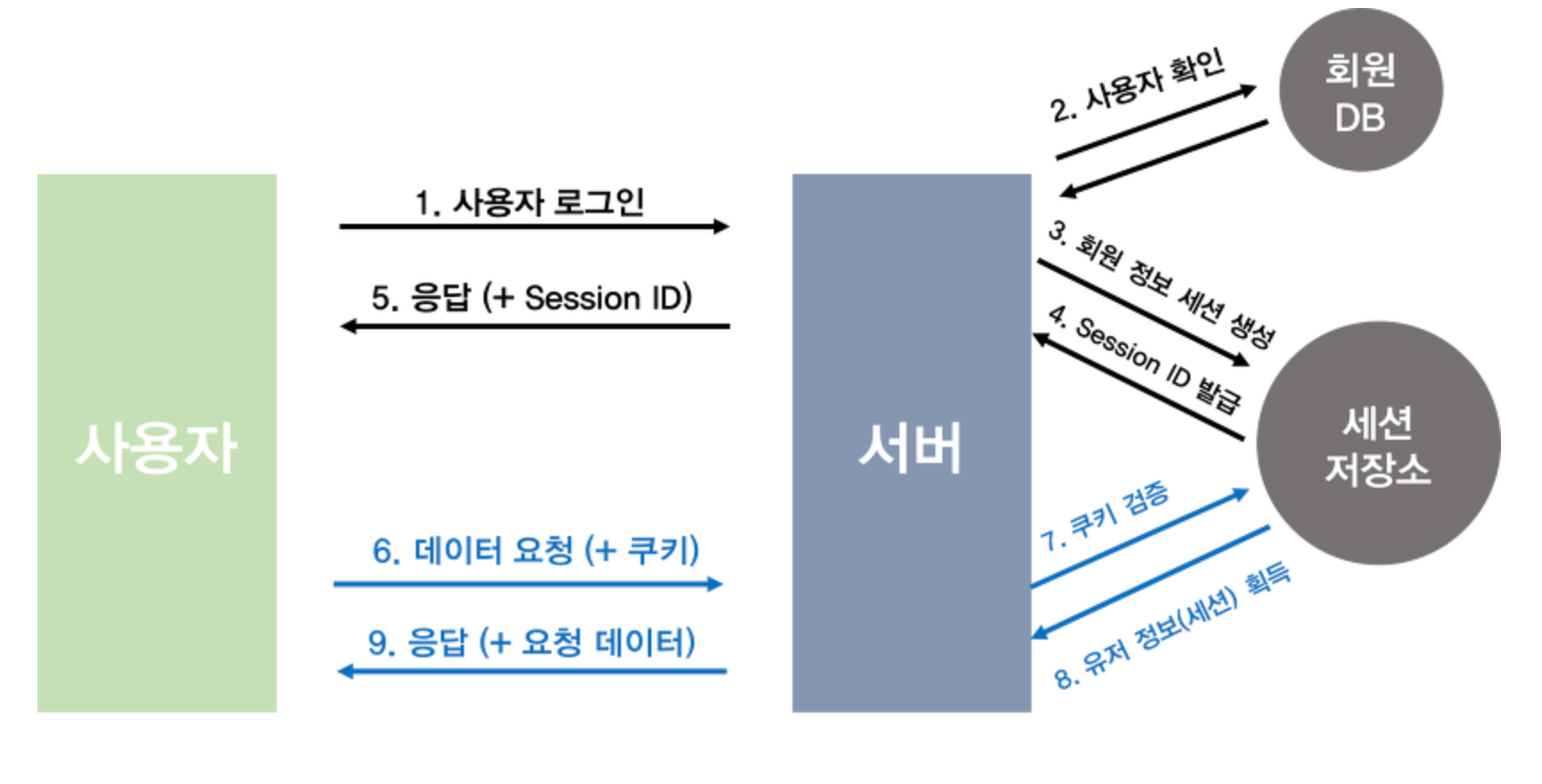
- 사용자가 로그인 요청을 보냅니다.
- 서버는 DB의 유저 테이블을 뒤져서 아이디 비밀번호를 대조해봐야겠죠?
- 실제 유저테이블의 정보와 일치한다면 인증을 통과한 것으로 보고 “세션 저장소”에 해당 유저가 로그인 되었다는 정보를 넣습니다.
- 세션 저장소에서는 유저의 정보와는 관련 없는 난수인 session-id를 발급합니다.
- 서버는 로그인 요청의 응답으로 session-id를 내어줍니다.
- 클라이언트는 그 session-id를 쿠키라는 저장소에 보관하고 앞으로의 요청마다 세션아이디를 같이 보냅니다. (주로 HTTP header에 담아서 보냅니다!)
- 클라이언트의 요청에서 쿠키를 발견했다면 서버는 세션 저장소에서 쿠키를 검증합니다.
- 만약 유저정보를 받아왔다면 이 사용자는 로그인이 되어있는 사용자겠죠?
- 이후에는 로그인 된 유저에 따른 응답을 내어줍니다.아래는 그림의 각 번호에 따른 설명
① 장점
- 세션/쿠키 방식은 기본적으로 쿠키를 매개로 인증을 거치기 때문에 비교적 안전한 방식이다.
- 여기서 쿠키는 세션 저장소에 담긴 유저 정보를 얻기 위한 열쇠를 의미한다.
- 따라서 쿠키가 담긴 HTTP 요청이 도중에 노출되더라도 쿠키 자체(세션 ID)는 유의미한 값을 갖고있지 않다(중요 정보는 서버 세션)
- 헤더에 직접적으로 계정정보를 담아 인증을 거치는 것 보단 안전하다.
- 사용자 A는 1번, 사용자 B는 2번 이런식으로 고유의 ID값을 발급받게 된다. 그렇게 되면 서버에서는 쿠키 값을 받았을 때 일일이 회원정보를 확인할 필요 없이 바로 어떤 회원인지를 확인할 수 있어 서버의 자원에 접근하기 용이하다.
② 단점
- 장점 1에서 쿠키를 탈취당하더라도 안전할 수 있다고 언급했지만 문제가 하나 있다. 만일 A 사용자의 HTTP 요청을 B 사용자(해커)가 가로챘다면 그 안에 들어있는 쿠키도 충분히 훔칠 수 있다. 그리고 B 사용자는 그 훔친 쿠키를 이용해 HTTP 요청을 보내면 서버의 세션저장소에서는 A 사용자로 오인해 정보를 잘못 뿌려주게 된다.(세션 하이재킹 공격이라고 한다)
- 해결책 ↓
-
더보기1. HTTPS를 사용해 서버와 클라이언트 간의 주고받는 정보를 암호화하여 요청 자체를 탈취해도 안의 정보를 읽기 힘들게 한다. 2. 세션에 유효시간을 넣어준다.
- 서버에서 세션 저장소를 사용한다. 따라서 서버에서 추가적인 저장공간을 필요로 하게되고 자연스럽게 부하도 높아질 것.
인증 방식 (2) JWT 기반 인증

- JWT(JSON Web Token)란 인증에 필요한 정보들을 암호화시킨 토큰을 의미
- JWT 기반 인증은 쿠키/세션 방식과 유사하게 JWT 토큰(Access Token)을 HTTP 헤더에 실어 서버가 클라이언트를 식별한다.
- 아래는 그림의 각 번호에 따른 설명
-
더보기
- 사용자가 로그인 요청을 보냅니다.
- 서버는 DB의 유저 테이블을 뒤져서 아이디 비밀번호를 대조해봐야겠죠?
- 실제 유저테이블의 정보와 일치한다면 인증을 통과한 것으로 보고 유저의 정보를 JWT로 암호화 해서 내보냅니다
- 서버는 로그인 요청의 응답으로 jwt 토큰을 내어줍니다.
- 클라이언트는 그 토큰을 저장소에 보관하고 앞으로의 요청마다 토큰을 같이 보냅니다.
- 클라이언트의 요청에서 토큰을 발견했다면 서버는 토큰을 검증합니다.
- 이후에는 로그인 된 유저에 따른 응답을 내어줍니다.
① 장점
- 간편하다. 세션/쿠키는 별도의 저장소의 관리가 필요하다. 그러나 JWT는 발급한 후 검증만 하면 되기 때문에 추가 저장소가 필요 없다. 이는 Stateless 한 서버를 만드는 입장에서는 큰 강점이다. 여기서 Stateless는 어떠한 별도의 저장소도 사용하지 않는, 즉 상태를 저장하지 않는 것을 의미. 이는 서버를 확장하거나 유지,보수하는데 유리하다.
- 확장성이 뛰어나다. 토큰 기반으로 하는 다른 인증 시스템에 접근이 가능하다. 예를 들어 Facebook 로그인, Google 로그인, 카카오 OAuth2 로그인 등은 모두 토큰을 기반으로 인증을 한다. 이에 선택적으로 이름이나 이메일 등을 받을 수 있는 권한도 받을 수 있다.
- 동시 접속자가 많을 때 서버 측 부하를 낮춰줄 수 있다.
② 단점
- 이미 발급된 JWT에 대해서는 돌이킬 수 없다. 세션/쿠키의 경우 만일 쿠키가 악의적으로 이용된다면, 해당하는 세션을 지워버리면 된다. 하지만 JWT는 한 번 발급되면 유효기간이 완료될 때 까지는 계속 사용이 가능하다. 따라서 악의적인 사용자는 유효기간이 지나기 전까지 신나게 정보들을 털어갈 수 있다.
- 해결책 ↓
-
더보기기존의 Access Token의 유효기간을 짧게 하고 Refresh Token이라는 새로운 토큰을 발급한다. 그렇게 되면 Access Token을 탈취당해도 상대적으로 피해를 줄일 수 있다.
- Payload 정보가 제한적이다. 위에서 언급했다시피 Payload는 따로 암호화되지 않기 때문에 디코딩하면 누구나 정보를 확인할 수 있다. (세션/쿠키 방식에서는 유저의 정보가 전부 서버의 저장소에 안전하게 보관된다) 따라서 유저의 중요한 정보들은 Payload에 넣을 수 없다.
- JWT의 길이. 세션/쿠키 방식에 비해 JWT의 길이는 길다. 따라서 인증이 필요한 요청이 많아질 수록 서버의 자원낭비가 발생하게 된다. = 비용 증가
- 구현의 복잡도가 증가한다.
- Secret key 유츌 시 JWT 조작 가능하다.
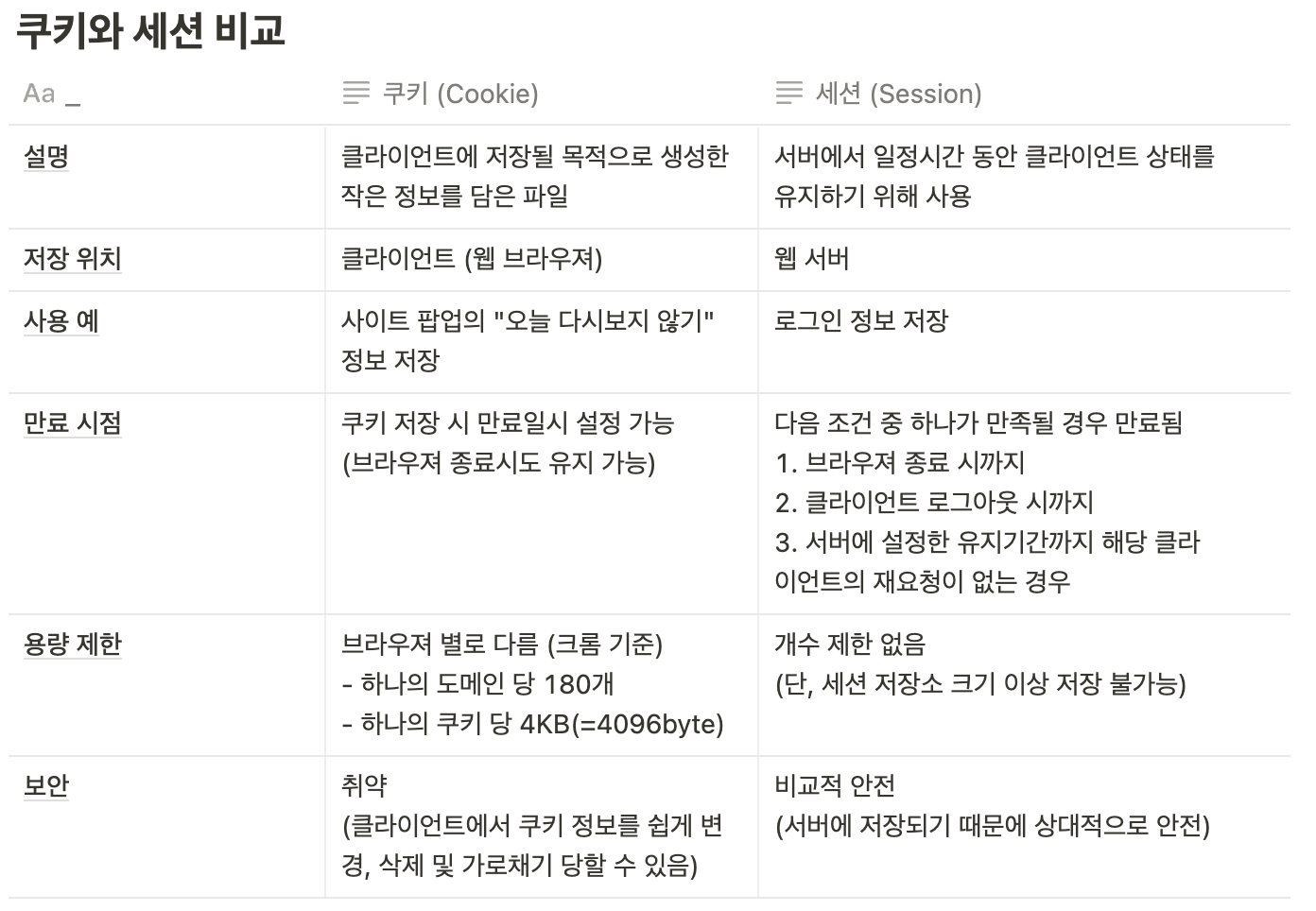
쿠키세션과 JWT의 차이
- 가장 큰 차이점은 세션/쿠키는 세션 저장소에 유저의 정보를 넣는 반면, JWT는 토큰 안에 유저의 정보들이 넣는다는 점
- 물론 클라이언트 입장에서는 HTTP 헤더에 세션ID나 토큰을 실어서 보내준다는 점에서는 동일하나, 서버 측에서는 인증을 위해 암호화를 하냐, 별도의 저장소를 이용하냐는 차이가 발생한다.
자료 출처 :
- 스파르타 코딩클럽 강의자료
- https://tansfil.tistory.com/58
'Coding > Spring' 카테고리의 다른 글
| [참고자료] 생성자와 의존성 주입 (기술매니저님 작성글) (0) | 2022.12.07 |
|---|---|
| + (추가) JWT 사용 흐름 재정리 (0) | 2022.12.07 |
| [17] 숙련주차 과제 (개념 부분 - 키워드 정리) (0) | 2022.12.07 |
| [16] IntelliJ 단축키 모음 (0) | 2022.12.07 |
| [15] JPA (2) 심화 (0) | 2022.12.07 |