메모리 주소
① 16진수
- 컴퓨터과학에서는 데이터를 처리하기 위해 숫자를 10진수나 2진수 대신 16진수(Hexadecimal)로 표현하는 경우가 많다.
- 16진수를 사용하면 10진수보다 2진수를 간단하게 나타낼 수 있는 장점이 있기 때문
② 10진수를 16진수로 바꾸어보기
JPG 이미지 파일은 항상 255 216 255 로 시작되고 이것은 10진수다. 하지만 실제 컴퓨터 내에서는 10진수를 사용하지 않는다. 컴퓨터는 0과 1만을 이해할 수 있기 때문.

- 먼저 255 216 255를 2진수로 나타내보면 <그림 1>과 같다.
- 2진수로 모든 데이터를 표현하기에는 너무 길어지기 때문에 16진수로 바꾸어 보면,
- 2^4(2의 4제곱)이 16이기 때문에 4bits씩 두 덩어리로 나누어 보면 0000 부터 1111까지는 16진수로 표현할 수 있다.
- 그렇다면 16진수에서 10부터 15까지는 어떻게 표기할까? 10은 a, 11은 b, …, 15는 f를 대입하여 사용
- 4bits씩 16진수로 변환 후 0x를 붙혀 뒤에 오는 문자들이 16진수임을 알려준다.
③ 16진수의 유용성
- ASCII 코드에 의해 “A, B, C”는 10진수로 65, 66, 67에 해당
- 컴퓨터는 10진수를 이해할 수 없으므로 2진수로 표현해보면 "01000001 01000010 01000011"이 된다.
- 하지만 16진수로 표현하면 2진수로 표현했을 때 보다 훨씬 간단해 진다.
- 컴퓨터는 8개의 비트가 모인 바이트 단위로 정보를 표현는데,
- 2개의 16진수는 1byte의 2진수로 변환되기 때문에 정보를 표현하기 매우 유용

⑤ 메모리 주소
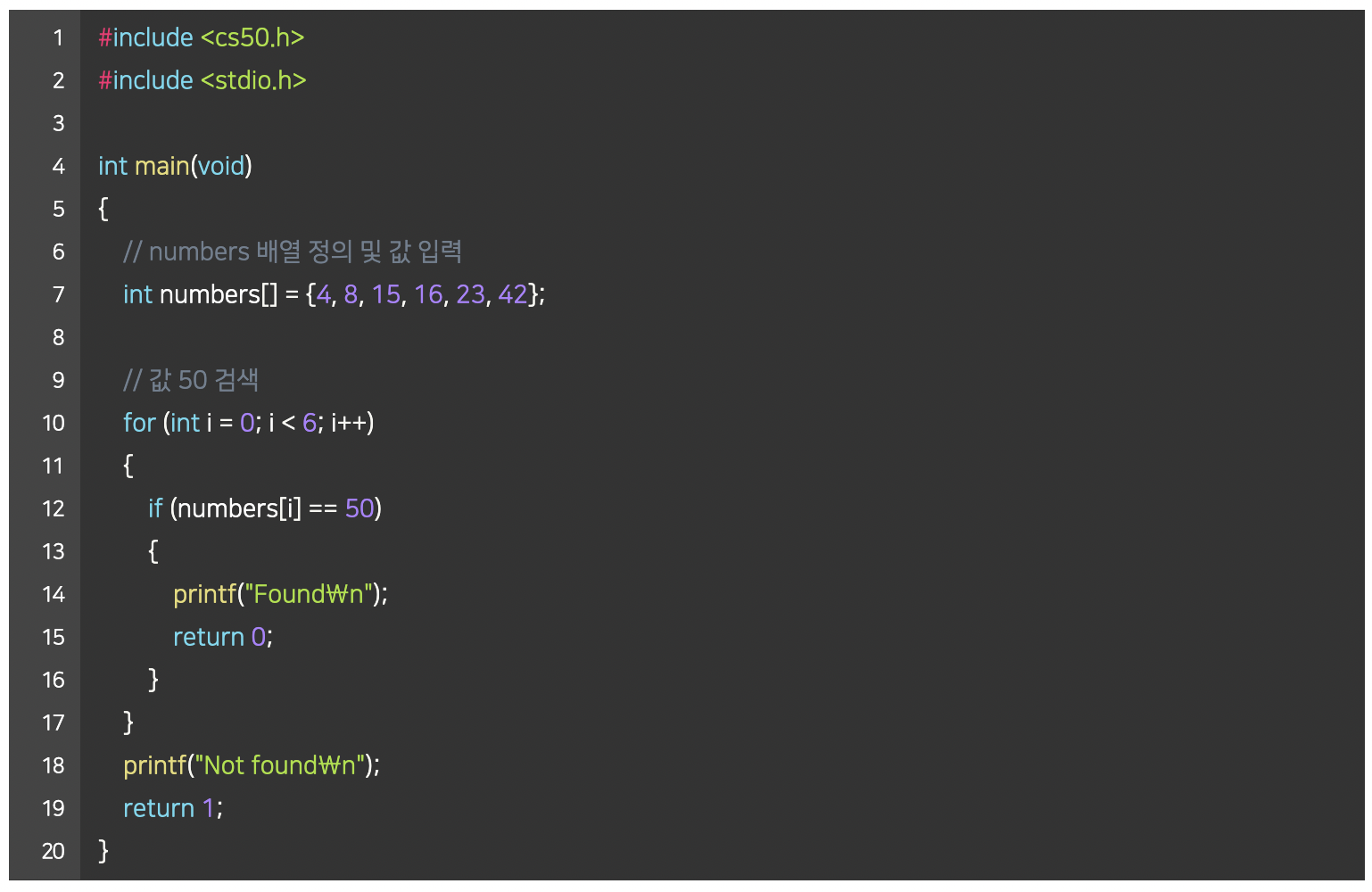
- 정수형 변수 n에 50이라는 값을 저장하고 출력한다고 생각해 보자.
- n 이라는 값은 int 타입이므로, 우리 컴퓨터의 메모리 어딘가에 4바이트 만큼의 자리를 차지하며 저장되어 있을 것
- C에서는 변수의 메모리상 주소를 받기 위해 ‘&’이라는 연산자를 사용할 수 있다.

- 예를 들어, 위와 같은 코드를 실행하면 ‘0x7ffe00b3adbc’와 같은 값을 얻을 수 있고, 이는 변수 n의 16진법으로 표현된 메모리의 주소이다.
- 반대로 ‘*’를 사용하면 그 메모리 주소에 있는 실제 값을 얻을 수 있다.

- 위 코드는 먼저 n의 주소를 얻고, 또 다시 그 주소에 해당하는 값을 얻어와 출력한 것이므로 결국 ‘50’이라는 값이 출력된다.
포인터
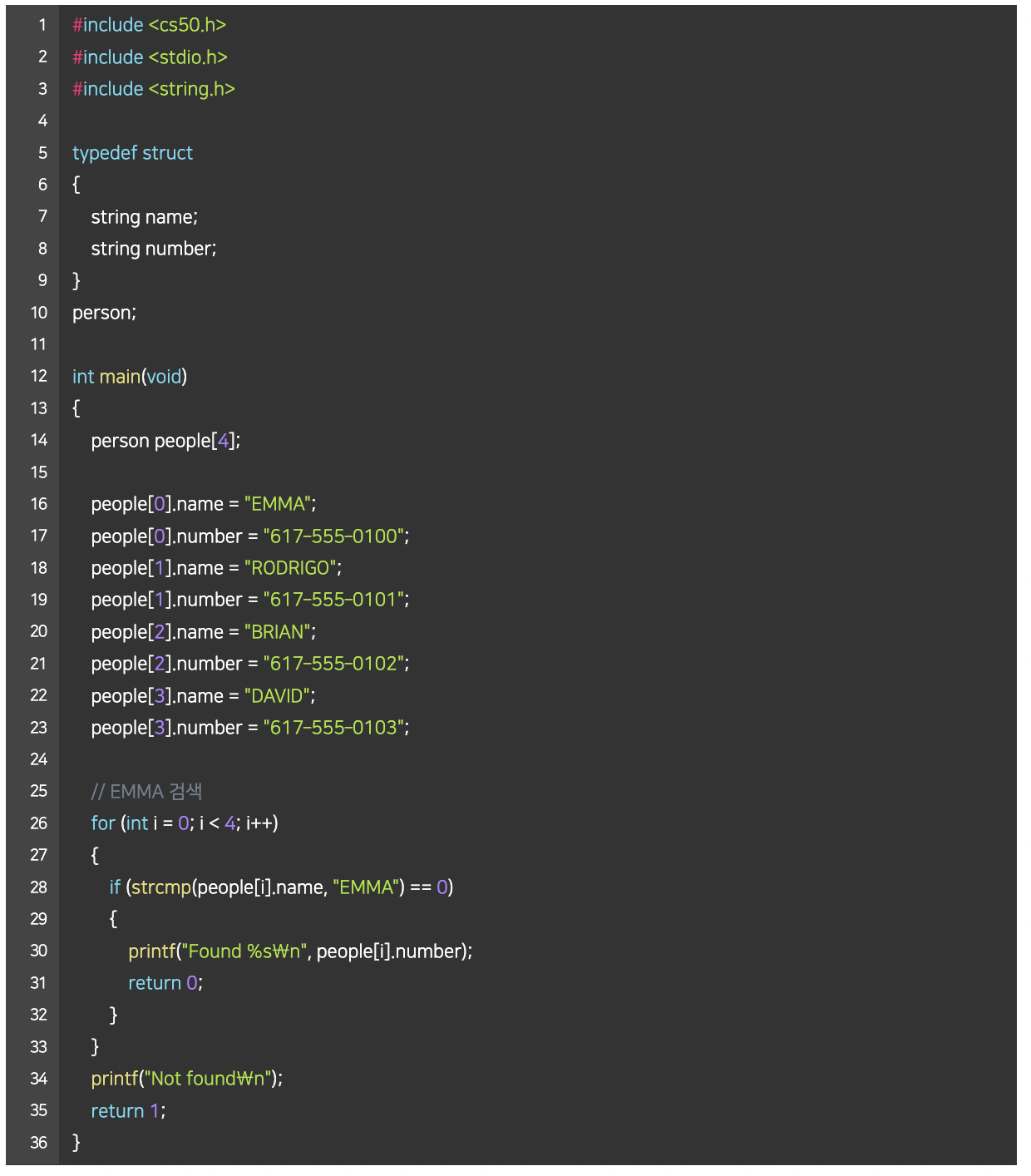
- 지난 강의에서 배웠던 ‘*’ 연산자는 어떤 메모리 주소에 있는 값을 받아오게 해준다.
- 이 연산자를 이용해서 포인터 역할을 하는 변수를 선언할 수도 있다.

- 위 코드를 보면 정수형 변수 n에는 50이라는 값이 저장되어 있다.
- 그리고 *p라는 포인터 변수에 &n 이라는 값, 즉 변수 n의 주소를 저장한다.
- int *p 에서 p앞의 *는 이 변수가 포인터라는 의미이고, int 는 이 포인터가 int 타입의 변수를 가리킨다는 의미
- 따라서 첫 번째 printf문과 같이 포인터 p의 값, 즉 변수 n의 주소를 출력하거나, 두 번째 printft문과 같이 포인터 p가 가리키는 변수의 값, 즉 변수 n의 값을 출력할 수도 있다.
실제 컴퓨터 메모리에서 변수 p는 아래와 같이 저장될 수 있다.

하지만 아래 그림과 같이 실제로 p의 값, 즉 n의 주소값을 생각하지 않고, 추상적으로 단지 p가 n을 가리키고 있다는 것만 생각해도 된다.

'boostcourse > CS50' 카테고리의 다른 글
| CS50 5. 메모리(3) - 메모리 할당과 해제/ 메모리 교환, 스택, 힙 (0) | 2022.10.25 |
|---|---|
| CS50 5. 메모리(2) - 문자열, 문자열 비교, 문자열 복사 (0) | 2022.10.24 |
| CS50 4. 알고리즘(3) - 정렬 알고리즘의 실행시간, 재귀, 병합 정렬 (0) | 2022.10.24 |
| CS50 4. 알고리즘(2) - 선형 검색, 버블 정렬, 선택 정렬 (0) | 2022.10.24 |
| CS50 4. 알고리즘(1) - 검색 알고리즘, 알고리즘 표기법 (0) | 2022.10.24 |