1. 어려웠던 부분: 과제를 복습하면서 NoArgsConstructor, AllArgsConstructor, RequiredArgsConstructor을 정확히 어떤 상황에 사용해야하는지 궁금해 졌다. 그 외 과제를 하면서 궁금했던 부분을 미경님이랑 혁수님이랑 같이 얘기하면서 정리해서 기술매니저님 순회시간에 여쭤봤다. 위에 언급한 어노테이션 뿐만 아니라, @Builder를 비롯한 코드에 적혀있는 어노테이션의 정확한 역할이 궁금해다. 어제 어노테이션을 정리하긴 했지만, 필드 생성자 메소드 클래스 모든 개념이 자리잡히지 않은 상태에서 생성자 때문이야 !! 라고 설명이 되어있어서 정리를 해도 이해가 되지 않았던 것 같다.
결론은, 자바 기본이 탄탄해야 뭐든 이해를 할 수 있다는 것. 내일은 다시한번 필드와 생성자를 정리해 봐야 겠다.
2. 느낀 점 : 스프링 참 어렵다. 어렵다고 들었는데, 정말 어렵다 ^_ㅠ ㅎ 오늘은 입문주차 강의자료를 하나도 빠짐없이 꼼꼼히 다시 읽어봤다. 아무래도 이번주에 과제를 시작하면서 정리를 다 끝내지 못했기 때문에, 일단 과제 레벨2 구현은 미뤄두고 놓쳤던 부분을 더 잡고 가자고 생각했다. 일단 입문주차는 80% 정도는 이해가 된 것 같다. 그리고 이어서 매운 맛인 JPA부분을 공부했다. 정말 어렵다. 어려워도 해야지 뭐 어쩌겠어.
3. 새로 알게 된 내용:
인텔리제이 단축키 정리
JPA 너란 녀석 쉽지 않다.
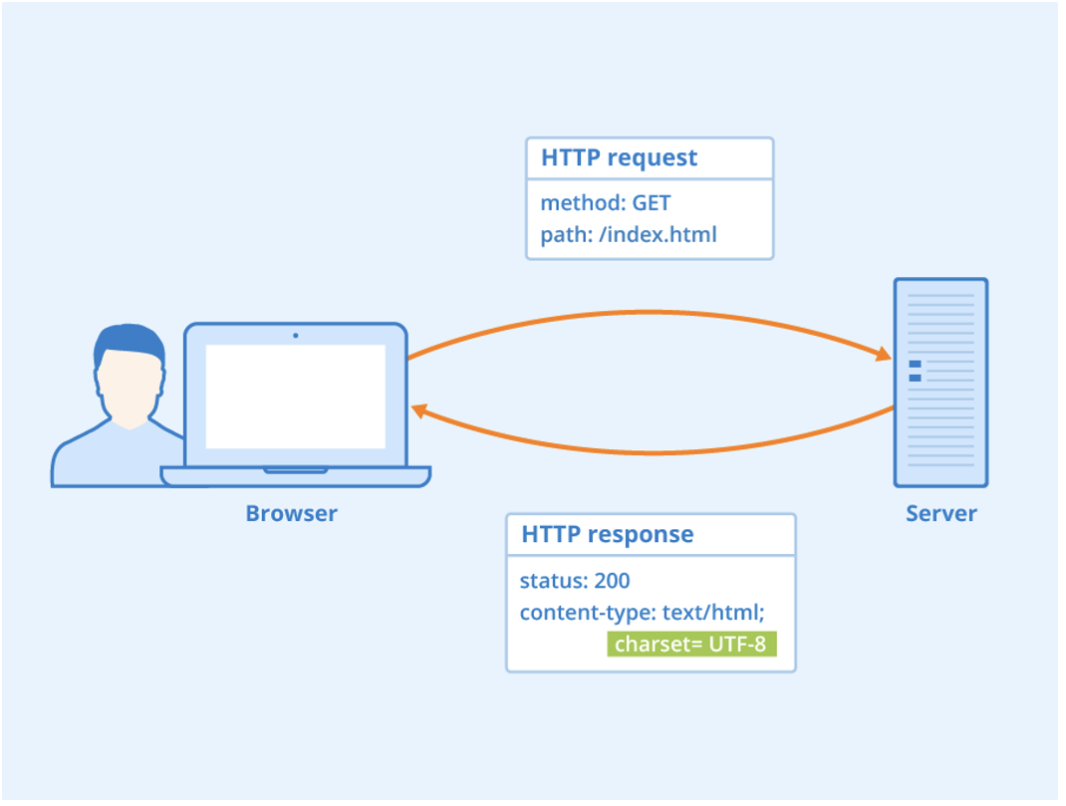
HTTP request 날려요 ~ response 날려요 ~ 무슨 의미인지 다시 짚고 가기
정규식표현
과제로 구현한 코드 리팩토링 + 어노테이션 살펴보기
4. 셀프칭찬 (오늘 잘한 일): 과제를 통해 얻는 부분도 많지만, 이해하지 못한 개념, 놓쳤던 개념을 다시 꼼꼼히 짚어보고 흡수하려고 한 오늘. 남들 보다 한발자국 느리긴 하지만, 그럴수록 탄탄하게 다지고 가자는 나의 마음을 칭찬해 주자. 조급해 하지 말자!
5. 이번주 할 일: Auth, JWT, Java chap09-1 공부, 이전 기수들 실전프로젝트 살펴보기/ 의존성 주입
트랜잭션의 지속성(durability)은 영속성이라고도 하는데 트랜잭션이 성공적으로 완료된 후 데이터베이스에 반영한 수행 결과는 어떠한 경우에도 손실되지 않고 영구적이어야 함을 의미한다. 즉, 시스템에 장애가 발생하더라도 트랜잭션 작업 결과는 없어지지 않고 데이터베이스에 그대로 남아있어야 한다는 의미다.
① 영속성 컨텍스트란 ?
출처 자바 ORM 표준 JPA - https://product.kyobobook.co.kr/detail/S000000935744
영속성 컨텍스트란 엔티티를 영구 저장 하는 환경 이라는 뜻
어플리케이션(자바 코드 그 자체)이 데이터베이스에서 꺼내온 데이터 객체를 보관하는 역할을 한다.
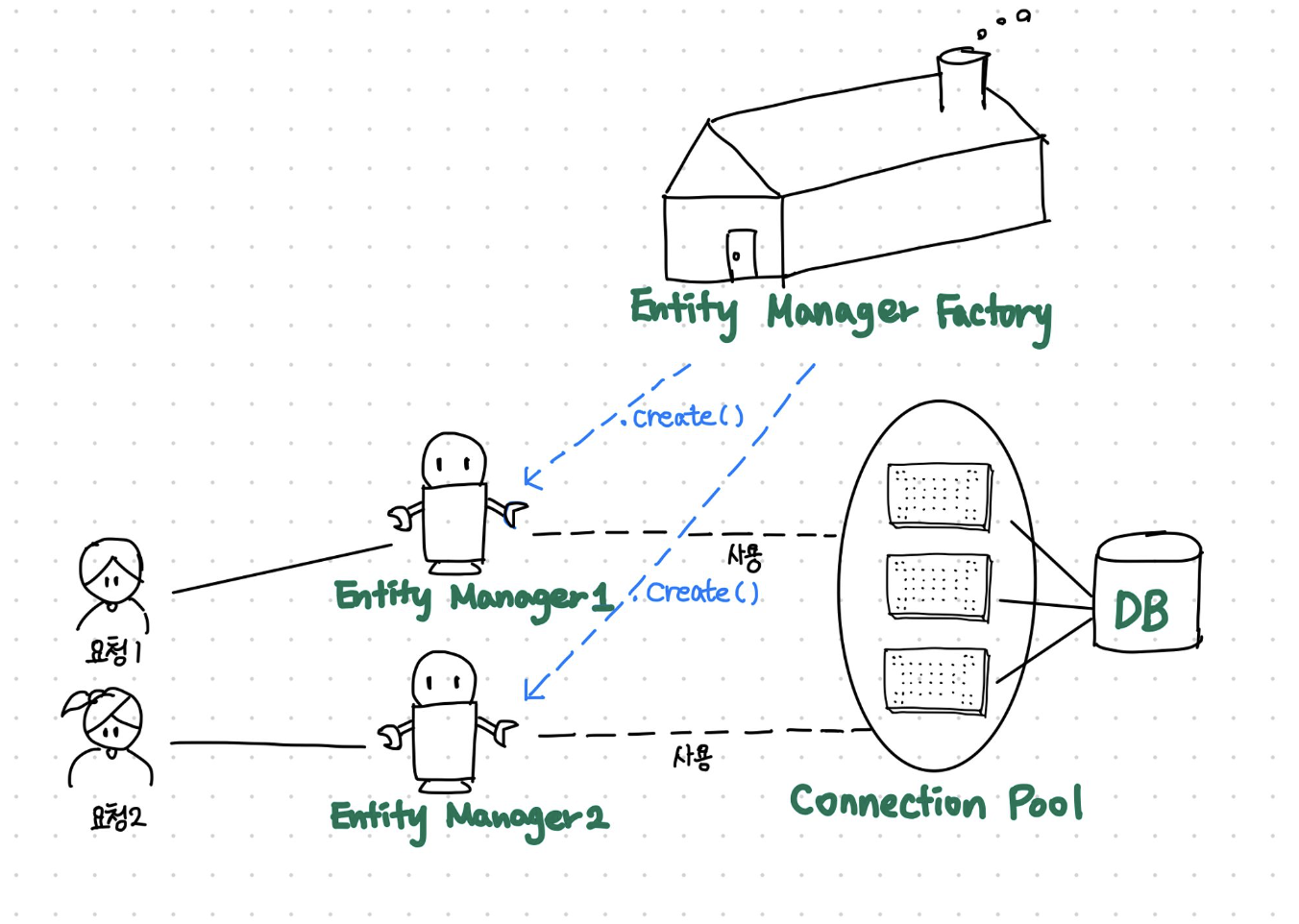
영속성 컨텍스트는 엔티티 매니저를 통해 엔티티를 조회하거나 저장할때 엔티티를 보관하고 관리한다.
엔티티 매니저마다 개별적으로 부여되는, 어떠한 논리적 공간같은 개념으로 비유적으로 이해할 수 있다.
자바의 엔티티 객체를 엔티티 매니저마다 가지고 있는 영속성 컨텍스트라는 공간에다 넣고 빼고 하면서 사용하는 것
“영속화 한다” 라는 말을 “엔티티 매니저가 자기의 영속성 컨텍스트에 넣어준다”로 이해할 수 있다.
② JPA 엔티티의 상태
비영속(New) : 영속성 컨택스트와 관계가 없는 새로운 상태. 해당 객체의 데이터가 변경되거나 말거나 실제 DB의 데이터와는 관련없고, 그냥 Java 객체인 상태
// 엔티티를 생성
Member minsook = new Member();
member.setId("minsook");
member.setUsername("민숙");
영속(Managed) : 엔티티 매니저를 통해 엔티티가 영속성 컨텍스트에 저장되어 관리되고 있는 상태. 이와 같은 경우 데이터의 생성, 변경등을 JPA가 추적하면서 필요하면 DB에 반영한다.
// 엔티티 매니저를 통해 영속성 컨텍스트에 엔티티를 저장
em.persist(minsook);
준영속(Detached) : 영속성 컨택스트에서 관리되다가 분리된 상태
// 엔티티를 영속성 컨택스트에서 분리
em.detach(minsook);
// 영속성 컨텍스트를 비우기
em.clear();
// 영속성 컨택스트를 종료
em.close();
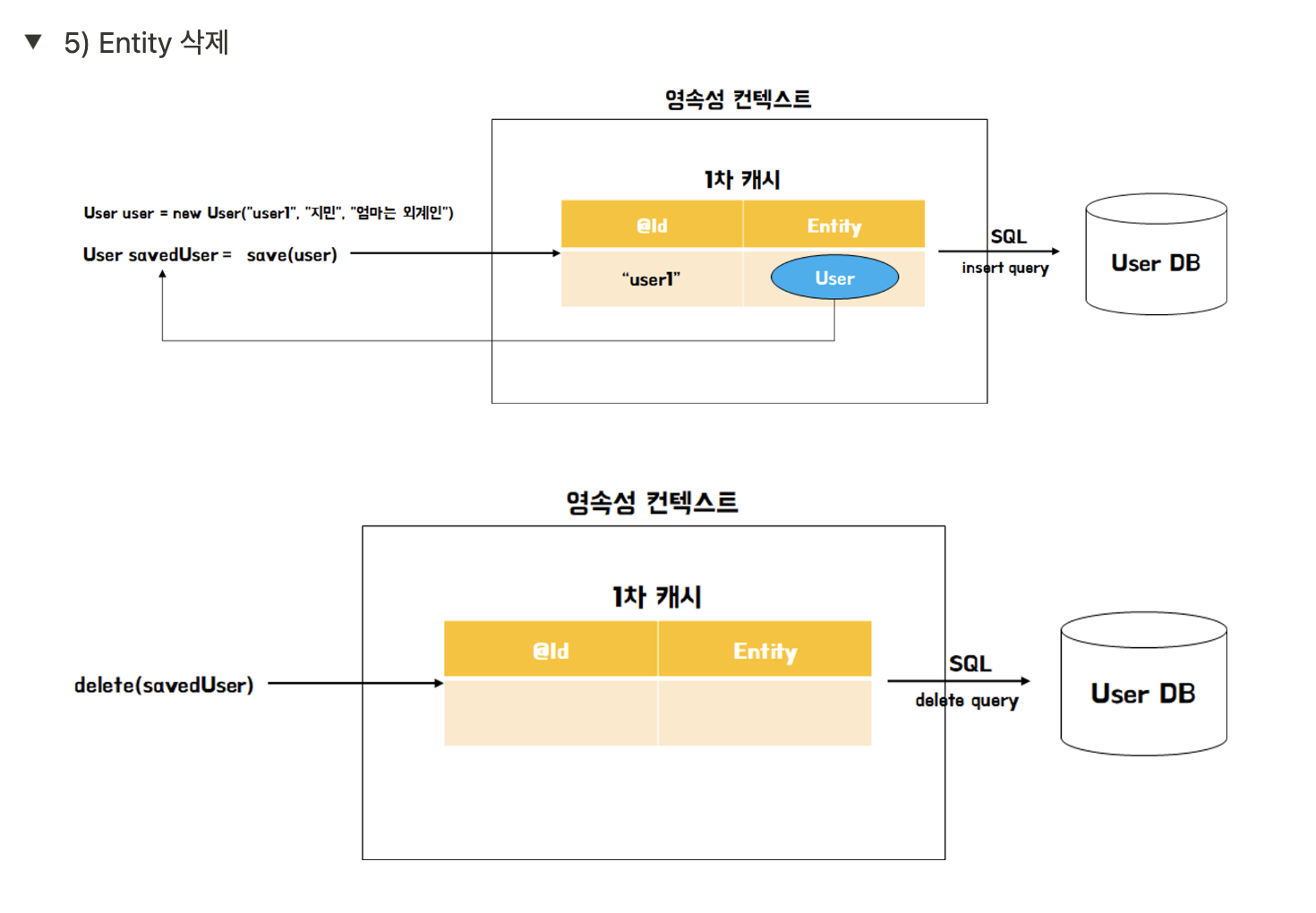
삭제(Removed) : 영속성 컨택스트에서 삭제된 상태
em.remove(minsook)
영속성 컨텍스트는 어떻게, 왜 이렇게 설계되어있을까?
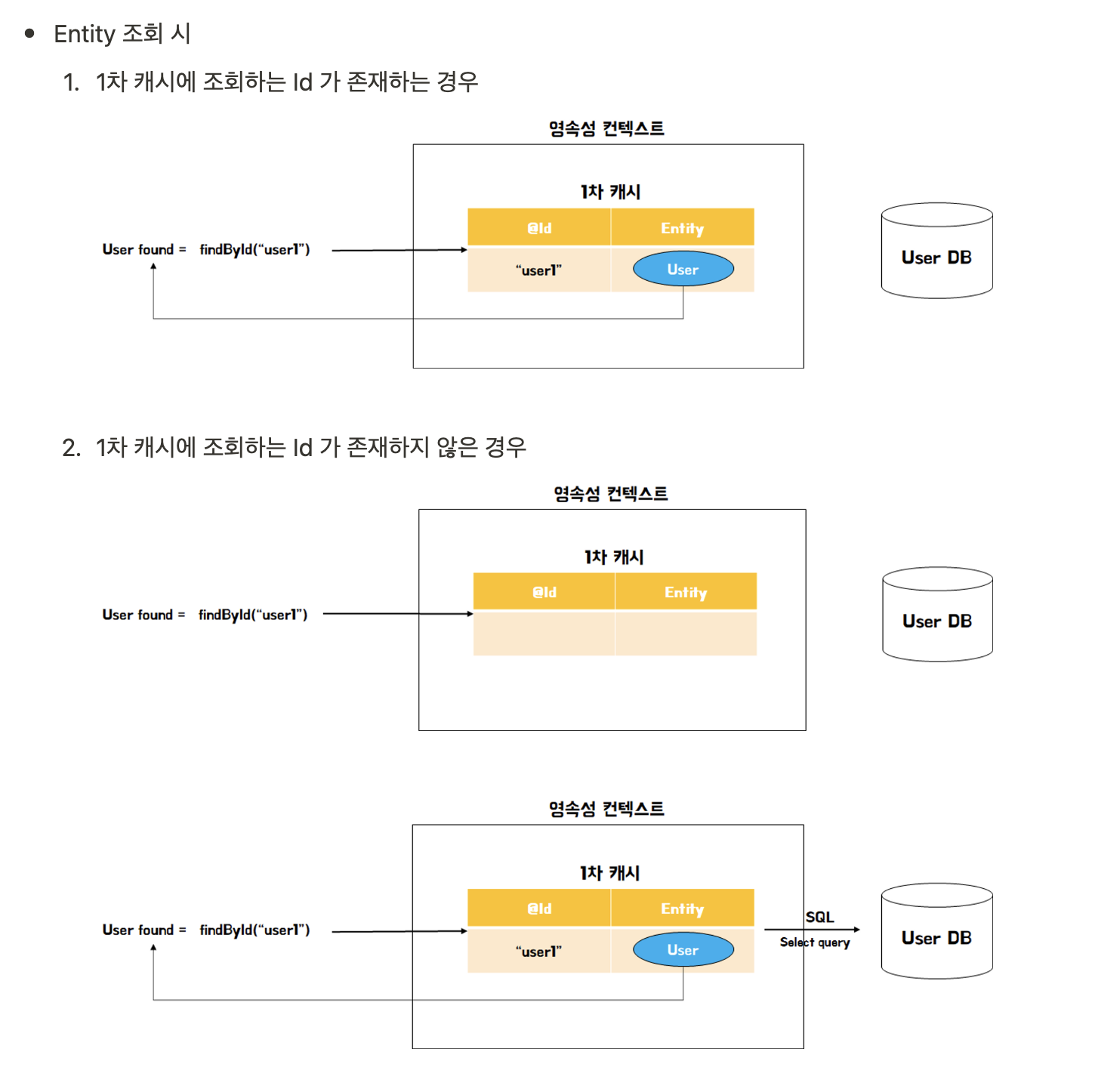
① 1차 캐시라는 것을 가지고 있다.
DB를 이용하는 작업은 상대적으로 부하와 비용이 심한 작업이다. 자바 어플리케이션 상에서 데이터를 조회 사용할일이 아주 잦은데, 그럴때마다 DB로 “SELECT * FROM….”과 같은 SQL쿼리를 내는 일은 막아야 한다. 굳이 DB에 접근하지 않아도 요청을 보다 가볍게 처리할 수 있도록 하기위해 영속성 컨텍스트 내부에 1차캐시를 둔다.
find(”memberB”)와 같은 로직이 있을 때 먼저 1차 캐시를 조회한다.
있으면 해당 데이터를 반환한다.
없으면 그 때 실제 DB로“SELECT * FROM….”의 쿼리를 내보낸다. (DB접근)
그리고 반환하기 전에 1차캐시에 저장하고 반환해준다.
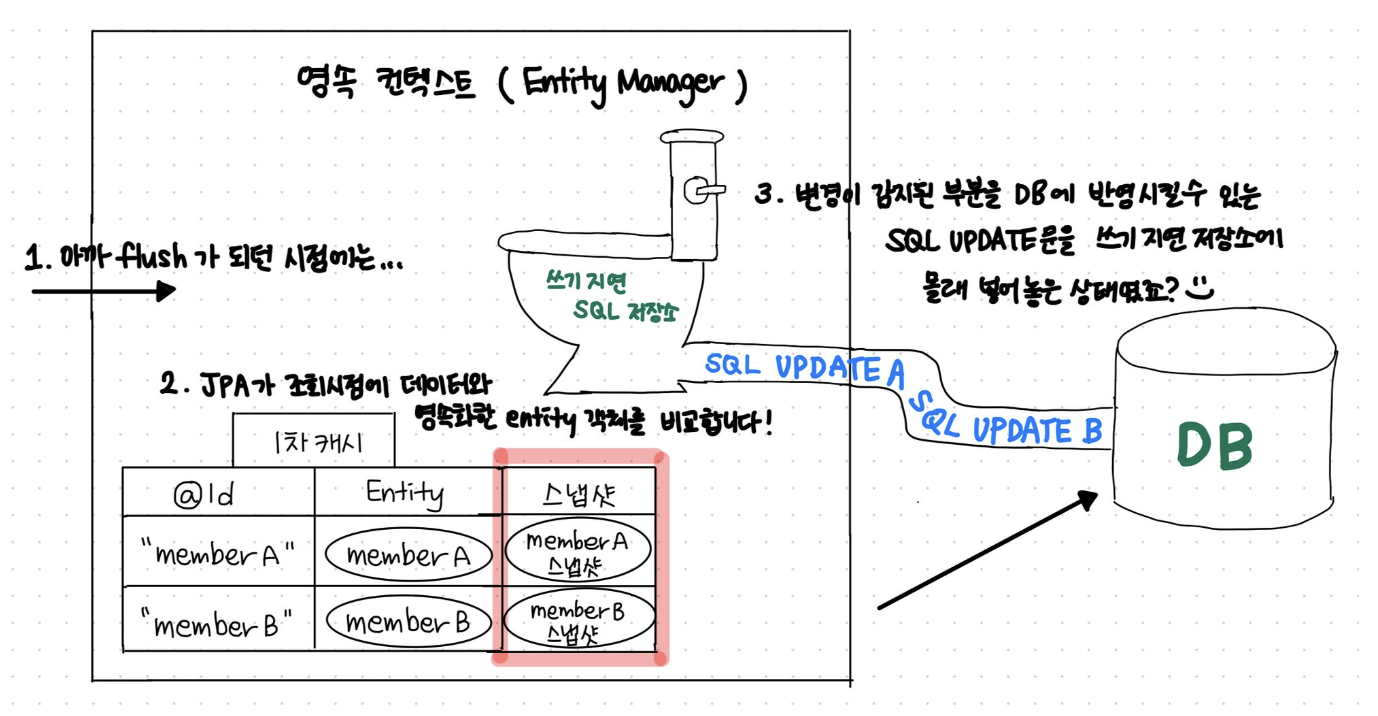
② “쓰기 지연 SQL 저장소”가 있다.
비슷한 맥락으로 MemberA, MemberB를 생성할 때 마다 DB를 다녀오는건 비효율적이기 때문에, 굳이 여러번 DB를 방문하지 않도록 내부에 “쓰기 지연 SQL 저장소”를 두고 있다.
memberA, memberB를 영속화 하고
entityManager.commit() 메서드를 호출하면
내부적으로 쓰기 지연 SQL 저장소에서 Flush가 일어나고
“INSERT A”, “INSERT B”와 같은 쓰기 전용 쿼리들이 DB로 흘러들어간다.
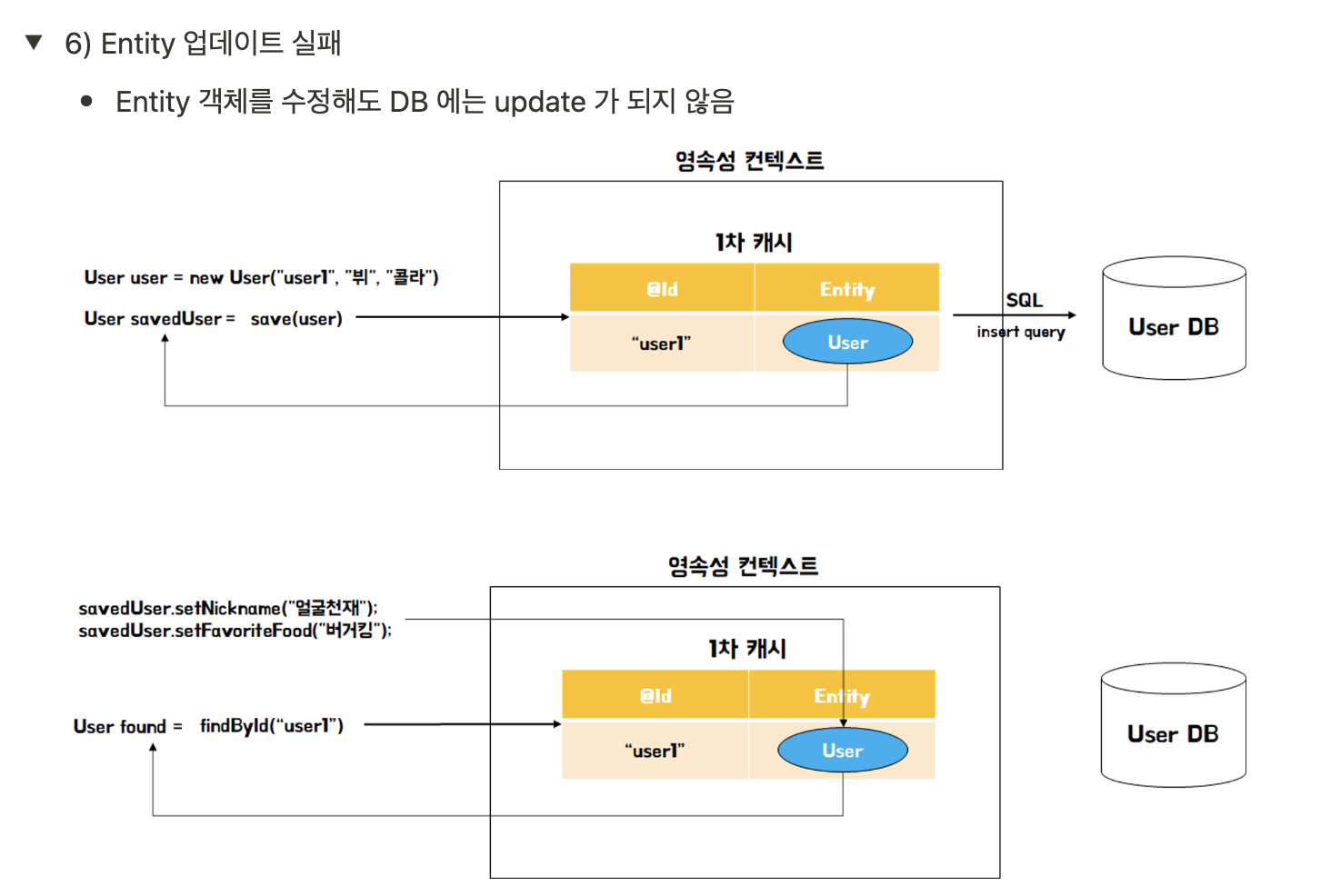
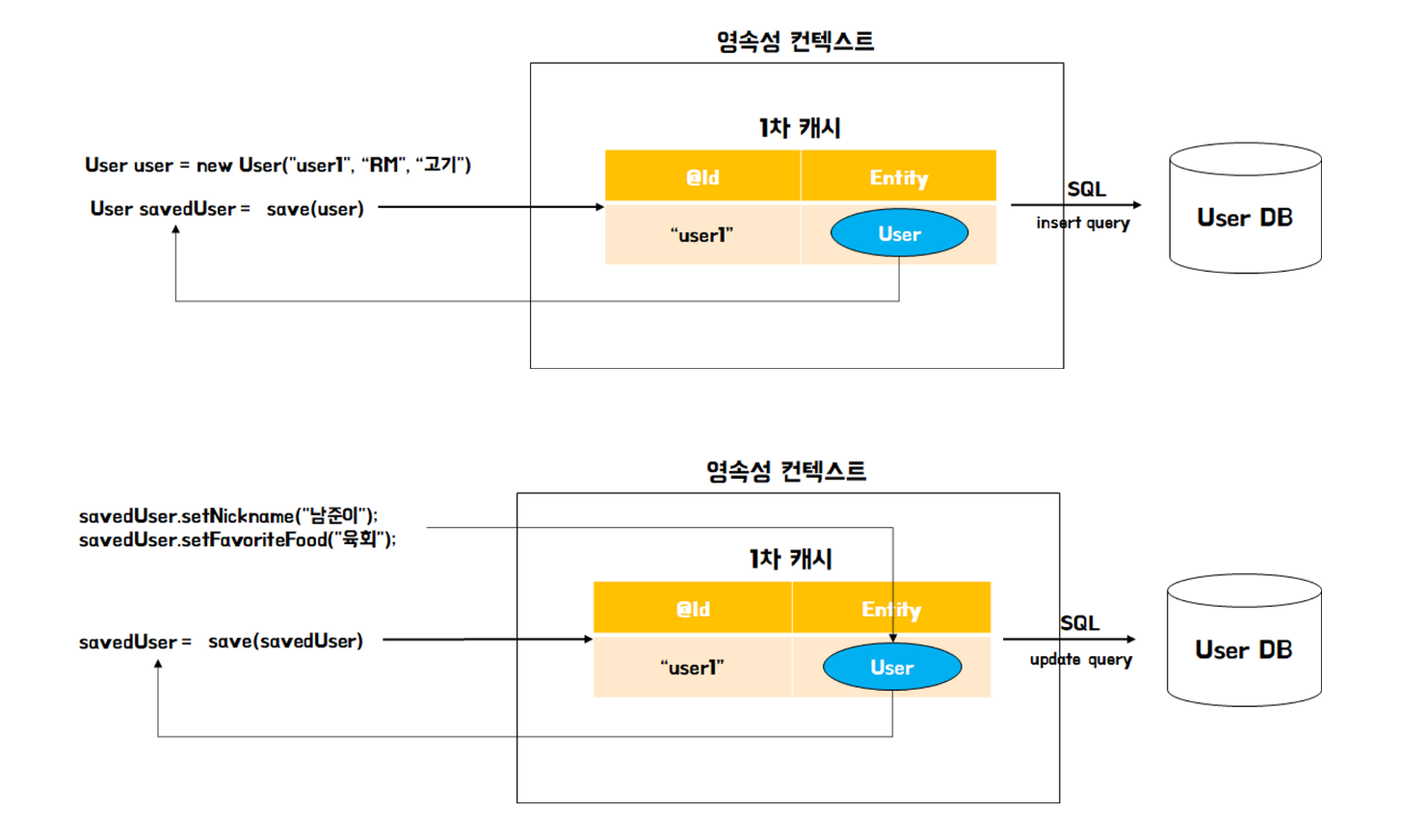
③ DirtyChecking을 통해 데이터의 변경을 감지해서 자동으로 수정해준다.
JPA는 1차캐시와 쓰기지연 SQL 저장소를 이용해서 변경과 수정을 감지해준다.
1. 사실 1차 캐시에는 DB의 엔티티의 정보만 저장하는것이 아니다.
2. 해당 엔티티를 조회한 시점의 데이터의 정보를 같이 저장해둔다.
3. 그리고 엔티티객체와 조회 시점의 데이터가 다르다면 변경이 발생했다고 감지한다.
4. 해당 변경 부문을 반영 할 수 있는 UPDATE 쿼리를 작성해둔다.
④ 데이터의 어플리케이션 단의 동일성을 보장해준다.
값이 같은 데이터가 들어오면 같은 데이터로 취급한다.
엔티티 매핑 심화 - 기본 엔티티 매핑 관련
@Entity
@Table (name="USER")
public class Member {
@Id
@Column (name = "user_id")
private String id;
private String username;
private Integer age;
@Enumerated (EnumType. STRING)
private RoleType userRole;
// @Enumerated (EnumType. ORDINAL)
// private RoleType userRole;
@Temporal (TemporalType. TIMESTAMP)
private Date createdDate;
@Temporal (TemporalType. TIMESTAMP)
private Date modifiedDate;
}
@Entity
기본 생성자는 필수!!
final 클래스, enum, interface 등에는 사용 할 수 없다.
저장할 필드라면 final을 사용할 수 없다.
@Table
엔티티와 매핑할 테이블의 이름
@Column
객체 필드를 테이블 컬럼에 매핑하는데 사용
생략 가능하다.
속성들은 자주 쓸 일이 없고, 특정 속성은 무시무시한 effect가 있으니 이름을 지정 할 때 아니고는 보통 생략하기도 한다.
@Enumerated
Java Enum을 테이블에서 사용한다고 생각하면 된다.
속성으로는 Ordinal, String이 있는데, String인경우 해당 문자열 그대로 저장해서 비용은 많이 들지만, 나중에 Enum이 변경되어도 위험할일이 없기 때문에 일반적으로는 String을 사용한다.
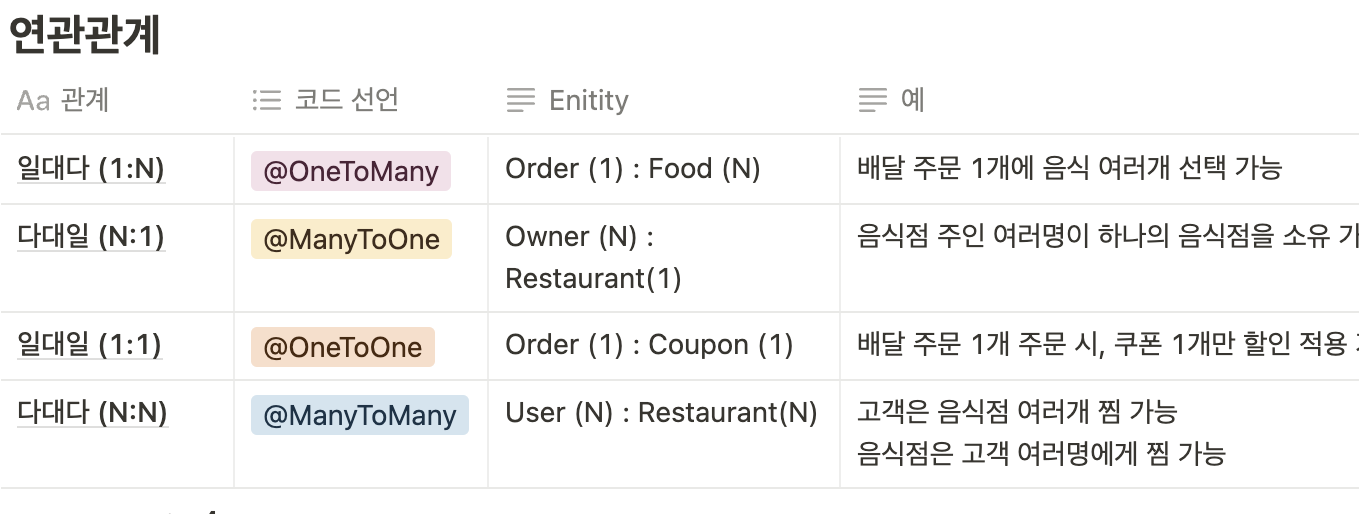
연관관계 관련 심화
단방향 연관관계
① @ManyToOne
이름 그대로 다대일(N:1) 관계라는 매핑 정보. ( “한명의 유저가 여러개의 주문” )
주요 속성으로는 optional, fetch, cascade가 있다.
optional은 말 그대로 false로 설정하면 항상 연관된 엔티티가 있어야 생성할 수 있다는 뜻.
② @JoinColumn(name="food_id")
외래 키를 매핑할 때 사용 (실제 데이터베이스에는 객체필드에는 해당 객체 테이블의 외래키가 들어간다)
기본적으로 @Column이 가지고 있는 필드 매핑관련 옵션 설정들과, 외래키 관련 몇가지 옵션이 추가되어있는 옵션
양방향 연관관계
@Getter
@Entity
@NoArgsConstructor
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String memberName;
@OneToMany(mappedBy = "member", fetch = FetchType.EAGER)
private List<Orders> orders = new ArrayList<>();
public Member(String memberName) {
this.memberName = memberName;
}
}
@Getter
@Entity
@NoArgsConstructor
public class Orders {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne
@JoinColumn(name = "food_id")
private Food food;
@ManyToOne
@JoinColumn(name = "member_id")
private Member member;
public Orders(Food food, Member member) {
this.food = food;
this.member = member;
}
}
@Getter
@Entity
@NoArgsConstructor
public class Food {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private String foodName;
@Column(nullable = false)
private int price;
@OneToMany(mappedBy = "food",fetch = FetchType.EAGER)
private List<Orders> orders = new ArrayList<>();
public Food(String foodName, int price) {
this.foodName = foodName;
this.price = price;
}
}
객체에는 사실 양방향 연관관계라는 것이 없다. 서로 다른 단방향으로 조회하는 로직 2개를 잘 묶어서 양방향인 것처럼 보이게 한 것 뿐
더 정확히는 멤버객체에 주문객체의 주소값을, 주문객체에는 멤버객체의 주소값을 가지고 있는 것
외래키는 연관관계가있는 두개의 테이블 중에서 하나의 테이블에만 있으면 충분하다.
따라서. 이런 차이로 인해 두 객체 연관관계 중 하나를 정해서 테이블의 외래키를 관리해야 하는데 이것을 연관관계의 주인이라 합니다.
연관관계의 주인만이 데이터베이스 연관관계와 매핑되고 외래 키를 관리(등록, 수정, 삭제) 하게 되어있다.
반면에 주인이 아닌 쪽은 읽기만 할 수 있다. 연관관계의 주인을 정한다는 것은 사실 외래 키 관리자를 선택하는 것!
연관관계의 주인에 의해 mappedBy 된다.
양방향 연관관계의 주의점
연관관계의 주인에는 값을 입력하지 않고, 주인이 아닌 곳에만 값을 입력하기. 데이터베이스에 외래 키값이 정상적으로 저장되지 않으면 이것부터 의심해봐야 한다.
해결 : 순수한 객체까지 고려한 양방향 연관관계 - 객체 관점에서 양쪽 방향에 모두 값을 입력해주는 것이 가장 안전
해결 2 : 연관관계 편의 메소드
프록시
엔티티를 조회할 때 연관된 엔티티들이 항상 사용되는 것은 아니다. 연관관계의 엔티티는 비즈니스 로직에 따라 사용될 때도 있지만 그렇지 않을 때도 있다. 실제 사용하다보면 유저의 선택이나, 특정 상황에 따라 연관관계로 맺어진 정보들이 전혀 필요 없을때가 많다.
JPA는 굳이 필요없는 DB 조회를 줄이면서 성능을 최적화한다. 이런 문제를 해결하려고 엔티티가 실제 사용될 때까지 데이터베이스 조회를 지연하는 방법을 제공하는데 이것을 지연 로딩이라 한다.
지연 로딩 기능을 사용하려면 실제 엔티티 객체 대상에 데이터베이스 조회를 지연할 수 있는 가짜 객체가 필요한데 이것을 프록시 객체라고 한다.
즉시 로딩 : 엔티티를 조회할 때 연관된 엔티티도 함께 조회 @ManyToOne(fetch = FetchType.EAGER)
지연 로딩 : 연관된 엔티티를 실제 사용할 때 조회, 설정 방법 : @ManyToOne(getch = FetchType.LAZY)
@ManyToOne, @OneToOne: 즉시 로딩(FetchType.EAGER)
@OneToMany, @ManyToMany: 지연 로딩(FetchType.LAZY)
기본적으로 “즉시로딩”은 연관된 엔티티를 조인해서 다 긁어와버리는 것이고, ”지연로딩”은 실제로 가짜 객체를 이용하면, 그때 별도의 쿼리가 나간다고 생각하면 된다.
하지만 즉시로딩은, 처음부터 모든 테이블에 조인을 걸어버리고 별도로 쿼리가 나가는 경우가 생기기에, 연관관계가 많고 복잡할수록 비용이 기하급수적으로 늘어나기에, 정확하게 이해하고 필요한 상황이 아니라면, 가급적으로 모두 지연로딩을 걸어두는게 일반적이다.
그렇다면 굳이 필요가 없다면, @ManyToOne(FetchType.Lazy)를 사용하면 된다.
영속성 전이?
특정 엔티티를 영속 상태로 만들 때 연관된 엔티티도 함께 영속 상태로 만들고 싶으면 영속성 전이기능을 사용하면 된다.
JPA는 cascade 옵션으로 영속성 전이를 제공한다
예를들어 유저테이블과 메모 테이블이 있는데, 영속화한 유저객체가 있으면, 메모 테이블도 같이 영속화되어 같이 관리되는 것을 영속성 전이라고 한다.
Spring으로 개발을 하다 보면 DTO 또는 객체를 검증해야 하는 경우가 있다. 객체의 검증을 손쉽게 하는 방법 @Valid, @Vaildated 에 대해 알아보자!
1. @Valid를 이용한 유효성 검증
① @Valid의 개념 및 사용법
@Valid는 JSR-303 표준 스펙(자바 진영 스펙)으로써 빈 검증기(Bean Validator)를 이용해 객체의 제약 조건을 검증하도록 지시하는 어노테이션이다. JSR 표준의 빈 검증 기술의 특징은 객체의 필드에 달린 어노테이션으로 편리하게 검증을 한다는 것이다.
Spring에서는 일종의 어댑터인 LocalValidatorFactoryBean가 제약 조건 검증을 처리한다. 이를 이용하려면 LocalValidatorFactoryBean을 빈으로 등록해야 하는데, SpringBoot에서는 아래의 의존성만 추가해주면 해당 기능들이 자동 설정된다.
② @Valid의 동작 원리
모든 요청은 프론트 컨트롤러인 디스패처 서블릿을 통해 컨트롤러로 전달된다. 전달 과정에서는 컨트롤러 메소드의 객체를 만들어주는 ArgumentResolver가 동작하는데, @Valid 역시 ArgumentResolver에 의해 처리가 된다.
대표적으로 @RequestBody는 Json 메세지를 객체로 변환해주는 작업이 ArgumentResolver의 구현체인 RequestResponseBodyMethodProcessor가 처리하며, 이 내부에서 @Valid로 시작하는 어노테이션이 있을 경우에 유효성 검사를 진행한다. (이러한 이유로 @Valid가 아니라 커스톰 어노테이션인 @ValidMangKyu여도 동작한다.)
만약 @ModelAttribute를 사용중이라면 ModelAttributeMethodProcessor에 의해 @Valid가 처리된다.그리고 검증에 오류가 있다면 MethodArgumentNotValidException 예외가 발생하게 되고, 디스패처 서블릿에 기본으로 등록된 예외 리졸버(Exception Resolver)인 DefaultHandlerExceptionResolver에 의해 400 BadRequest 에러가 발생한다.
이러한 이유로 @Valid는 기본적으로컨트롤러에서만 동작하며 기본적으로 다른 계층에서는 검증이 되지 않는다. 다른 계층에서 파라미터를 검증하기 위해서는 @Validated와 결합되어야 한다.
2. @Validated를 이용한 유효성 검증
① @Validated의 개념 및 사용법
입력 파라미터의 유효성 검증은 컨트롤러에서 최대한 처리하고 넘겨주는 것이 좋다. 하지만 개발을 하다보면 불가피하게 다른 곳에서 파라미터를 검증해야 할 수 있다. Spring에서는 이를 위해 AOP 기반으로 메소드의 요청을 가로채서 유효성 검증을 진행해주는 @Validated를 제공하고 있다. @Validated는 JSR 표준 기술이 아니며 Spring 프레임워크에서 제공하는 어노테이션 및 기능이다.
특정 ArgumnetResolver에 의해 유효성 검사가 진행되었던 @Valid와 달리, @Validated는 AOP 기반으로 메소드 요청을 인터셉터하여 처리된다. @Validated를 클래스 레벨에 선언하면 해당 클래스에 유효성 검증을 위한 AOP의 어드바이스 또는 인터셉터(MethodValidationInterceptor)가 등록된다. 그리고 해당 클래스의 메소드들이 호출될 때 AOP의 포인트 컷으로써 요청을 가로채서 유효성 검증을 진행한다.
이러한 이유로 @Validated를 사용하면 컨트롤러, 서비스, 레포지토리 등 계층에 무관하게 스프링 빈이라면 유효성 검증을 진행할 수 있다. 대신 클래스에는 유효성 검증 AOP가 적용되도록 @Validated를, 검증을 진행할 메소드에는 @Valid를 선언해주어야 한다.
이러한 이유로 @Valid에 의한 예외는 MethodArgumentNotValidException이며, @Validated에 의한 예외는 ConstraintViolationException이다. 이를 알고 있으면 나중에 예외 처리를 할 때 도움이 된다.