1. 어려웠던 부분: 오늘 미리프로젝트 제출을 완료 했다. 마지막날까지 추가기능을 구현하느라 부랴부랴 깃헙에 각자 작업한 파일을 합치는데, 깃헙 머지하는 과정에서 꽤나 고생을 했다. 과제를 제출하는 순간까지 반환타입을 통일시키는 리팩토링을 하고 회원탈퇴 추가기능을 구현하느라 하루종일 머리가 깨졌는데, 와중에 내가 의지하던 우리 팀원 유리님이 오늘 부로 하차하신다는 말을 전하셔서 마음이 잘 잡히질 않았다.
2. 느낀 점 :
스프링을 공부하는 반 사람들 중 5명이 이번주에 하차했다. 다른 분들은 그렇다 쳐도, 친하게 지내던 유리님이 하차를 하시니까 마음이 너무 싱숭생숭한 하루였다.
반 사람들이 열심히 하지 않거나 못하는 사람을 감자라고 칭하는 걸 이번주가 되서야 알았다. 감자를 캐네 마네 하는 이야기를 처음 들었는데, 사실 잘하는 분들 입장에선 충분히 그 마음이 이해가 된다. 이곳에 온 이유가 취업이다보니 당연히 비슷한 실력을 가진 사람들과 프로젝트를 구현하고 싶을 것이다. 근데 한편으론, 그럼 나도 감자인가? 다음주부터 프로젝트를 연이어 3개 정도 하게 될텐데 내가 민폐를 끼치는 감자 포지션인가? 라는 생각이 들었다. 유리님 마음처럼 나도 생각이 많아지는 그런 하루였다.
3. 새로 알게 된 내용: 깃헙으로 협업을 할 땐, 일단 시작이 되는 Root 파일을 만들어야 한다. 거기에 필요한 디펜던시를 설치해주고 그리고 공통으로 사용하게될 엔티티나 커먼패키지를 먼저 만든 뒤에 작업을 해야 더 효율적으로 작업을 할 수 있다.
4. 셀프칭찬 (오늘 잘한 일): 지난주까지 남의 코드를 봐야만 내 코드를 작성할 수 있었는데, 이젠 남의 코드 보고 내 코드로 만드는 일은 좀 익숙해 진 것 같다. 그리고 오늘 처음으로 회원탈퇴 기능 구현 코드를 작성했다. 지성님이 개념공부보다 일단 코드를 더 많이 보라고 조언해 주셨는데, 확실히 코드를 많이 보다보니 흐름을 좀 더 읽을 수 있게 된 것 같다.
1. 어려웠던 부분: 오늘은 혼공자책과 자바 객체지향의 원리와 이해 책을 보면서 자바 기초에 대한 부분을 더 다지는 시간을 가졌다. 객체지향이라는 개념을 접한지 벌써 한달이 지났지만 여전히 참 애매하고 어렵다. 객체 = 유일무이한 존재, 각각의 객체가 갖고있는 공통된 특징을 클래스라고 한다. 클래스 설계는 어디까지를 공통된 특징으로 삼을 것인가에 대한 고민이 필요한 것 같다. 나를 하나의 객체라고 생각했을때, 어떤 클래스 집단에 속하고 싶은지 생각해 보게 되는 그런 개념 공부의 날이었다.
2. 느낀 점 : 오늘 팀원분들과 함께 코드리뷰를 했는데, 생각보다 시간이 오래 걸렸다. 다들 한줄씩 친절하게 설명을 해주셔서 다시한번 흐름을 파악할 수 있었던 것 같다. 요즘 미국 빅테크 기업들에서 대규모 layoff가 일어나고 있는데, 실제로 내가 구독하는 유튜브 두명 모두 해당 대상자가 되셨다는 영상을 봤다. 개발자 하면 먹고살 걱정 안하겠지 했는데, 시장경제가 안좋으니 마냥 그렇게 생각할 수는 없겠구나 라는 생각이 들었다. 중꺾마 라고 했던가. 어쩌겠어 일단 닥친 것 부터 해야지. 인생의 시련은 앞으로의 성장을 위한 불가피한 요소인 것 같다. 매일이 쉽지 않지만, 나를 더 믿어보자.
3. 새로 알게 된 내용: 트랜잭션에 대한 공부를 했다. 그리고 트러블슈팅 정리를 통해 다음 코드 작성땐 통해 어떤 부분을 유의해야 하는지 정리할 수 있었다.
4. 셀프칭찬 (오늘 잘한 일): 코드 리팩토링을 통해 중복되는 Dto를 하나로 합쳐주고, 클래스명이나 메소드 이름도 나중에 쉽게 알아볼 수 있도록 리팩토링하는 작업을 해주었다. 그리고 추가 작업이었던 회원탈퇴 부분을 구현했다. 미경님의 조언이 있었지만, 이 과제를 하면서 처음으로 내가 스스로 코드를 구현한 것 같아서 헛공부는 아니었구나 라는 생각이 들었다. 스스로 알게모르게 어느정도 CRUD를 이해하고 있다는 생각이 들어서 마음이 어제보다 가벼워 졌다.
5. 내일 할 일: 심화주차 강의자료 정리 마무리(Testcode, 예외처리), 언어스터디(chap 11), 내코드 + 다른사람 코드 보고 손코딩 다시해보기
여러 작업을 진행하다가 문제가 생겼을 경우 이전 상태로 롤백하기 위해 사용되는 것이 트랜잭션(Transaction)이다.
트랜잭션은 더 이상 쪼갤 수 없는 최소 작업 단위를 의미한다. 그래서 트랜잭션은 commit으로 성공 하거나 rollback으로 실패 이후 취소되어야 한다. 하지만 모든 트랜잭션이 동일한 것은 아니고 속성에 따라 동작 방식을 다르게 해줄 수 있다.
위에서 설명한 것과 마찬가지로 트랜잭션의 마무리 작업으로는 크게 2가지가 있다.
트랜잭션 커밋: 작업이 마무리 됨
트랜잭션 롤백: 작업을 취소하고 이전의 상태로 돌림
만약 여러 작업이 모두 마무리 되었다면 트랜잭션 커밋을 통해 작업이 마무리되었음을 알려주어 반영해야 하며, 만약 문제가 생겼다면 작업 취소를 위해 트랜잭션 롤백 처리를 해주어야 한다.
② Transaction의 기본 방법
Transaction은 2개 이상의 쿼리를 하나의 커넥션으로 묶어 DB에 전송하고, 이 과정에서 에러가 발생할 경우 자동으로 모든 과정을 원래대로 되돌려 놓는다. 이러한 과정을 구현하기 위해 Transaction은하나 이상의 쿼리를 처리할 때 동일한 Connection 객체를 공유하도록 한다.
2. Spring에서 Transaction의 사용법
① Spring의 Transaction
Spring은 코드 기반의 트랜잭션(Programmatic Transaction) 처리 뿐만 아니라 선언적 트랜잭션(Declarative Transaction)을 지원하고 있다. Spring이 제공하는 트랜잭션 템플릿 클래스를 이용하거나 설정파일, 어노테이션을 이용해서 트랜잭션의 범위 및 규칙을 정의할 수 있다. Spring에서는 주로 선언적 트랜잭션을 이용하는데, <tx:advice>태그 또는 @Transactional 어노테이션을 이용하는데,쿼리문을 처리하는 과정에서 에러가 났을 경우 자동으로 Rollback 처리를 해준다.
② Spring @Transactional
일반적으로 Spring에서는 Service Layer에서 @Transactional 을 추가하여 Transaction 처리를 한다. 아래의 예시는 상점과 관련된 Service 부분이고, 데이터의 조회만 일어나는 select 메소드에서는 @Transactional 을 활용하고 있지 않지만, 값을 추가하거나 변경 또는 삭제하는 insert, update, delete 메소드에는 @Transactional을 추가하여 트랜잭션을 설정해두었다.
package com.mang.store.service;
import com.mang.store.vo.StoreVO;
import org.springframework.transaction.annotation.Transactional;
import java.util.List;
public interface StoreService {
List<StoreVO> selectStoreInfoList(StoreVO storeVO);
StoreVO selectStoreInfo(StoreVO storeVO);
@Transactional
int insertStoreInfo(StoreVO storeVO);
@Transactional
int updateStoreInfo(StoreVO storeVO);
@Transactional
int deleteStoreInfo(StoreVO storeVO);
}
③ 비지니스 로직과의 결합
트랜잭션을 중구난방으로 적용하는 것은 좋지 않다. 대신 특정 계층의 경계를 트랜잭션 경계와 일치시키는 것이 좋은데, 일반적으로비지니스 로직을 담고 있는 서비스 계층의 메소드와 결합시키는 것이 좋다. 왜냐하면 데이터 저장 계층으로부터 읽어온 데이터를 사용하고 변경하는 등의 작업을 하는 곳이 서비스 계층이기 때문이다. 위와 같이 클래스 레벨에 트랜잭션 어노테이션을 붙여주면 메소드까지 적용이 된다.
@Service
@RequiredArgsConstructor
@Transactional(readOnly = true)
public class UserService {
private final UserRepository userRepository;
private final BCryptPasswordEncoder passwordEncoder;
public List<User> getUserList() {
return userRepository.findAll();
}
}
서비스 계층을 트랜잭션의 시작과 종료 경계로 정했다면, 테스트와 같은 특별한 이유가 아니고는 다른 계층이나 모듈에서 DAO에 직접 접근하는 것은 차단해야 한다. 트랜잭션은 보통 서비스 계층의 메소드 조합을 통해 만들어지기 때문에 DAO가 제공하는 주요 기능은 서비스 계층에 위임 메소드를 만들어둘 필요가 있다. 그리고 가능하면 다른 모듈의 DAO에 접근할 때는 서비스 계층을 거치도록 하는 것이 바람직하다.
⑤ 읽기 전용 트랜잭션의 공통화
클래스 레벨에는 공통적으로 적용되는 읽기전용 트랜잭션 어노테이션을 선언하고, 추가나 삭제 또는 수정이 있는 작업에는 쓰기가 가능하도록 별도로 @Transacional 어노테이션을 메소드에 선언하는 것이 좋다. 이를 체감하기는 힘들겠지만 약간의 성능적인 이점을 얻을 수 있다.
@Service
@RequiredArgsConstructor
@Transactional(readOnly = true)
public class UserService {
private final UserRepository userRepository;
private final BCryptPasswordEncoder passwordEncoder;
public List<User> getUserList() {
return userRepository.findAll();
}
@Transactional
public User signUp(final SignUpDTO signUpDTO) {
final User user = User.builder()
.email(signUpDTO.getEmail())
.pw(passwordEncoder.encode(signUpDTO.getPw()))
.role(UserRole.ROLE_USER)
.build();
return userRepository.save(user);
}
}
⑥ 테스트의 롤백
트랜잭션 어노테이션을 테스트에 붙이면테스트의 DB 커밋을 롤백해주는 기능이 있다.
DB와 연동되는 테스트를 할 때에는 DB의 상태와 데이터가 상당히 중요하다. 하지만 문제는 테스트에서 DB에 쓰기 작업을 하면 DB의 데이터가 바뀌는 것인데, 트랜잭션 어노테이션을 테스트에 활용하면 테스트를 진행하는 동안에 조작한 데이터를 모두 롤백하고 테스트를 진행하기 전의 상태로 만들어준다. 어떠한 경우에도 커밋을 하지 않기 때문에 테스트가 성공하거나 실패해도 상관이 없으며 심지어 예외가 발생해도 어떠한 문제가 발생하지 않는다. 강제로 롤백시키도록 설정되어 있기 때문이다.
@Transactional
@ExtendWith(SpringExtension.class)
@DataJpaTest
class UserRepositoryTest {
@Autowired
private UserRepository userRepository;
@Test
void findByEmailAndPw() {
final User user = User.builder()
.email("email")
.pw("pw")
.role(UserRole.ROLE_USER).build();
userRepository.save(user);
assertThat(userRepository.findAll().size()).isEqualTo(1);
}
}
하지만 테스트 메소드 안에서 진행되는 작업을 하나의 트랜잭션으로 묶고는 싶지만 강제 롤백을 원하지 않을 수 있다. 테스트의 작업을 그대로 DB에 반영하고 싶다면 @Rollback(false)를 이용해주면 된다. @Rollback은 메소드에만 적용가능하므로, 클래스 레벨에 부여하기를 원한다면 @TransactionConfiguration(defaultRollback=false) 를 이용하고, 롤백을 원하는 메소드에 @Rollback(true)를 이용하면 된다.
물론 여기서 auto_increment나 sequence 등에 의해 증가된 값은 롤백이 되지 않는다. 그렇기 때문에 테스트를 위해서는 별도의 데이터베이스로 연결을 하거나 또는 H2와 같은 휘발성(인메모리) 데이터베이스를 사용하는 것이 좋다.
3. Spring이 제공하는 Transaction(트랜잭션) 핵심 기술
Spring은 트랜잭션과 관련된 3가지 핵심 기술을 제공하고 있다. 그 3가지 핵심 기술은 다음과 같다.
트랜잭션(Transaction) 동기화
트랜잭션(Transaction) 추상화
AOP를 이용한 트랜잭션(Transaction) 분리
① 트랜잭션(Transaction) 동기화
JDBC를 이용하는 개발자가 직접 여러 개의 작업을 하나의 트랜잭션으로 관리하려면 Connection 객체를 공유하는 등 상당히 불필요한 작업들이 많이 생길 것이다.
Spring은 이러한 문제를 해결하고자 트랜잭션 동기화(Transaction Synchronization) 기술을 제공하고 있다. 트랜잭션 동기화는트랜잭션을 시작하기 위한 Connection 객체를 특별한 저장소에 보관해두고 필요할 때 꺼내쓸 수 있도록 하는 기술이다.
트랜잭션 동기화 저장소는 작업 쓰레드마다 Connection 객체를 독립적으로 관리하기 때문에, 멀티쓰레드 환경에서도 충돌이 발생할 여지가 없다. 그래서 다음과 같이 트랜잭션 동기화를 적용하게 된다.
// 동기화 시작
TransactionSynchronizeManager.initSynchronization();
Connection c = DataSourceUtils.getConnection(dataSource);
// 작업 진행
// 동기화 종료
DataSourceUtils.releaseConnection(c, dataSource);
TransactionSynchronizeManager.unbindResource(dataSource);
TransactionSynchronizeManager.clearSynchronization();
하지만 개발자가 JDBC가 아닌 Hibernate와 같은 기술을 쓴다면 위의 JDBC 종속적인 트랜잭션 동기화 코드들은 문제를 유발하게 된다. 대표적으로 Hibernate에서는 Connection이 아닌 Session이라는 객체를 사용하기 때문이다. 이러한 기술 종속적인 문제를 해결하기 위해 Spring은 트랜잭션 관리 부분을 추상화한 기술을 제공하고 있다.
② 트랜잭션(Transaction) 추상화
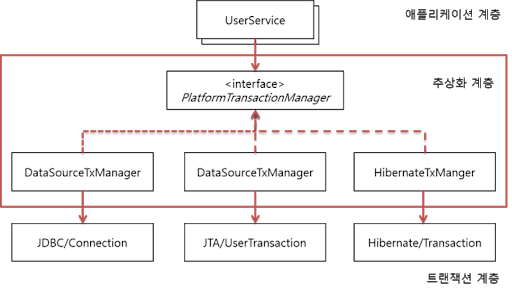
Spring은트랜잭션 기술의 공통점을 담은 트랜잭션 추상화 기술을 제공하고 있다. 이를 이용함으로써 애플리케이션에 각 기술마다(JDBC, JPA, Hibernate 등)종속적인 코드를 이용하지 않고도 일관되게 트랜잭션을 처리할 수 있도록 해주고 있다.
Spring이 제공하는 트랜잭션 경계 설정을 위한 추상 인터페이스는 PlatformTransactionManager 이다. 예를 들어 만약 JDBC의 로컬 트랜잭션을 이용한다면 DataSourceTxManager를 이용하면 된다.
이제 우리는 사용하는 기술과 무관하게 PlatformTransactionManager를 통해 다음의 코드와 같이 트랜잭션을 공유하고, 커밋하고, 롤백할 수 있게 되었다.
하지만 위와 같은 트랜잭션 관리 코드들이 비지니스 로직 코드와 결합되어 2가지 책임을 갖고 있다. Spring에서는 AOP를 이용해 이러한 트랜잭션 부분을 핵심 비지니스 로직과 분리하였다.
③ AOP를 이용한 트랜잭션(Transaction) 분리
예를 들어 다음과 같이트랜잭션 코드와 비지니스 로직 코드가 복잡하게 얽혀있는 코드가 있다고 하자.
public void addUsers(List<User> userList) {
TransactionStatus status = this.transactionManager.getTransaction(new DefaultTransactionDefinition());
try {
for (User user: userList) {
if(isEmailNotDuplicated(user.getEmail())){
userRepository.save(user);
}
}
this.transactionManager.commit(status);
} catch (Exception e) {
this.transactionManager.rollback(status);
throw e
}
}
위의 코드는 여러 책임을 가질 뿐만 아니라 서로 성격도 다르고 주고받는 것도 없으므로 분리하는 것이 적합하다.
하지만 위의 코드를 어떻게 분리할 것인지에 대한 고민을 해야 한다. 흔히 떠올릴 수 있는 방법으로는 내부 메소드로 추출하거나 DI로 합성을 이용해 해결하거나 상속을 이용할 수 있을 것이다.
하지만 위의 어떠한 방법을 이용하여도 트랜잭션을 담당하는 기술 코드를 완전히 분리시키는 것이 불가능하였다. 그래서 Spring에서는 마치 트랜잭션 코드와 같은 부가 기능 코드가 존재하지 않는 것 처럼 보이기 위해해당 로직을 클래스 밖으로 빼내서 별도의 모듈로 만드는 AOP(Aspect Oriented Programming, 관점 지향 프로그래밍)를 고안 및 적용하게 되었고, 이를 적용한트랜잭션 어노테이션(@Transactional)을 지원하게 되었다. 이를 적용하면 위와 같은 코드를 핵심 비지니스 로직만 다음과 같이 남길 수 있다.
@Service
@RequiredArgsConstructor
@Transactional
public class UserService {
private final UserRepository userRepository;
public void addUsers(List<User> userList) {
for (User user : userList) {
if (isEmailNotDuplicated(user.getEmail())) {
userRepository.save(user);
}
}
}
}
④ Spring 트랜잭션의 세부 설정
Spring의 DefaultTransactionDefinition이 구현하고 있는 TransactionDefinition 인터페이스는 트랜잭션의 동작방식에 영향을 줄 수 있는 네 가지 속성을 정의하고 있다. 해당 4가지 속성은 트랜잭션을 세부적으로 이용할 수 있게 도와주며, @Transactional 어노테이션에도 공통적으로 적용할 수 있다.
트랜잭션 전파
격리수준
제한시간
읽기전용
트랜잭션 전파
트랜잭션 전파란 트랜잭션의 경계에서 이미 진행중인 트랜잭션이 있거나 없을 때 어떻게 동작할 것인가를 결정하는 방식을 의미한다. 예를 들어 어떤 A 작업에 대한 트랜잭션이 진행중이고 B 작업이 시작될 때 B 작업에 대한 트랜잭션을 어떻게 처리할까에 대한 부분이다.
1. A의 트랜잭션에 참여(PROPAGATION_REQUIRED)
B의 코드는 새로운 트랜잭션을 만들지 않고 A에서 진행중이 트랜잭션에 참여할 수 있다. 이 경우 B의 작업이 마무리 되고 나서, 남은 A의 작업(2)을 처리할 때 예외가 발생하면 A와 B의 작업이 모두 취소된다. 왜냐하면 A와 B의 트랜잭션이 하나로 묶여있기 때문이다.
2. 독립적인 트랜잭션 생성(PROPAGATION_REQUIRES_NEW)
반대로 B의 트랜잭션은 A의 트랜잭션과 무관하게 만들 수 있다. 이 경우 B의 트랜잭션 경계를 빠져나오는 순간 B의 트랜잭션은 독자적으로 커밋 또는 롤백되고, 이것은 A에 어떠한 영향도 주지 않는다. 즉, 이후 A가 (2)번 작업을 하면서 예외가 발생해 롤백되어도 B의 작업에는 영향을 주지 못한다.
3. 트랜잭션 없이 동작(PROPAGATION_NOT_SUPPORTED)
B의 작업에 대해 트랜잭션을 걸지 않을 수 있다. 만약 B의 작업이 단순 데이터 조회라면 굳이 트랜잭션이 필요 없을 것이다.
이렇듯 이미 진행중인 트랜잭션이 어떻게 영향을 미칠 수 있는가에 대한 부분이 트랜잭션 전파 속성이다. 트랜잭션을 시작하는 것처럼 보이는 getTransaction() 코드가 begin이 아닌 get으로 이름이 지어진 이유도 여기에 있다. 해당 트랜잭션은 다른 트랜잭션에 묶여있을 수 있기 때문이다. 위에서 설명한 대표적인 처리 방법 외에도 다양한 처리 방법을 지원하고 있다.
격리 수준
모든 DB 트랜잭션은 격리수준을 가지고 있어야 한다. 서버에서는 여러 개의 트랜잭션이 동시에 진행될 수 있는데, 모든 트랜잭션을 독립적으로 만들고 순차 진행 한다면 안전하겠지만 성능이 크게 떨어질 수 밖에 없다. 따라서 적절하게 격리수준을 조정해서 가능한 많은 트랜잭션을 동시에 진행시키면서 문제가 발생하지 않도록 제어해야 한다. 이는 JDBC 드라이버나 DataSource 등에서 재설정할 수 있고, 트랜잭션 단위로 격리 수준을 조정할 수도 있다.
DefaultTransactionDefinition에 설정된 격리수준은 ISOLATION_DEFAULT로 DataSource에 정의된 격리 수준을 따른다는 것이다.
기본적으로는 DB나 DataSource에 설정된 기본 격리 수준을 따르는 것이 좋지만, 특별한 작업을 수행하는 메소드라면 독자적으로 지정해줄 필요가 있다.
제한시간
트랜잭션을 수행하는 제한시간을 설정할 수 있다. 제한시간의 설정은 트랜잭션을 직접 시작하는 PROPAGATION_REQUIRED나 PROPAGATION_REQUIRES_NEW의 경우에 사용해야만 의미가 있다.
읽기전용
읽기전용으로 설정해두면 트랜잭션 내에서 데이터를 조작하는 시도를 막아줄 수 있을 뿐만 아니라 데이터 액세스 기술에 따라 성능이 향상될 수 있다.
위에서 트랜잭션의 세부 설정들 외에도 Spring은 다양한 세부 설정들을 제공하고 있다. 이와 관련된 자세한 내용은 다음 포스팅에서 참고할 수 있다.
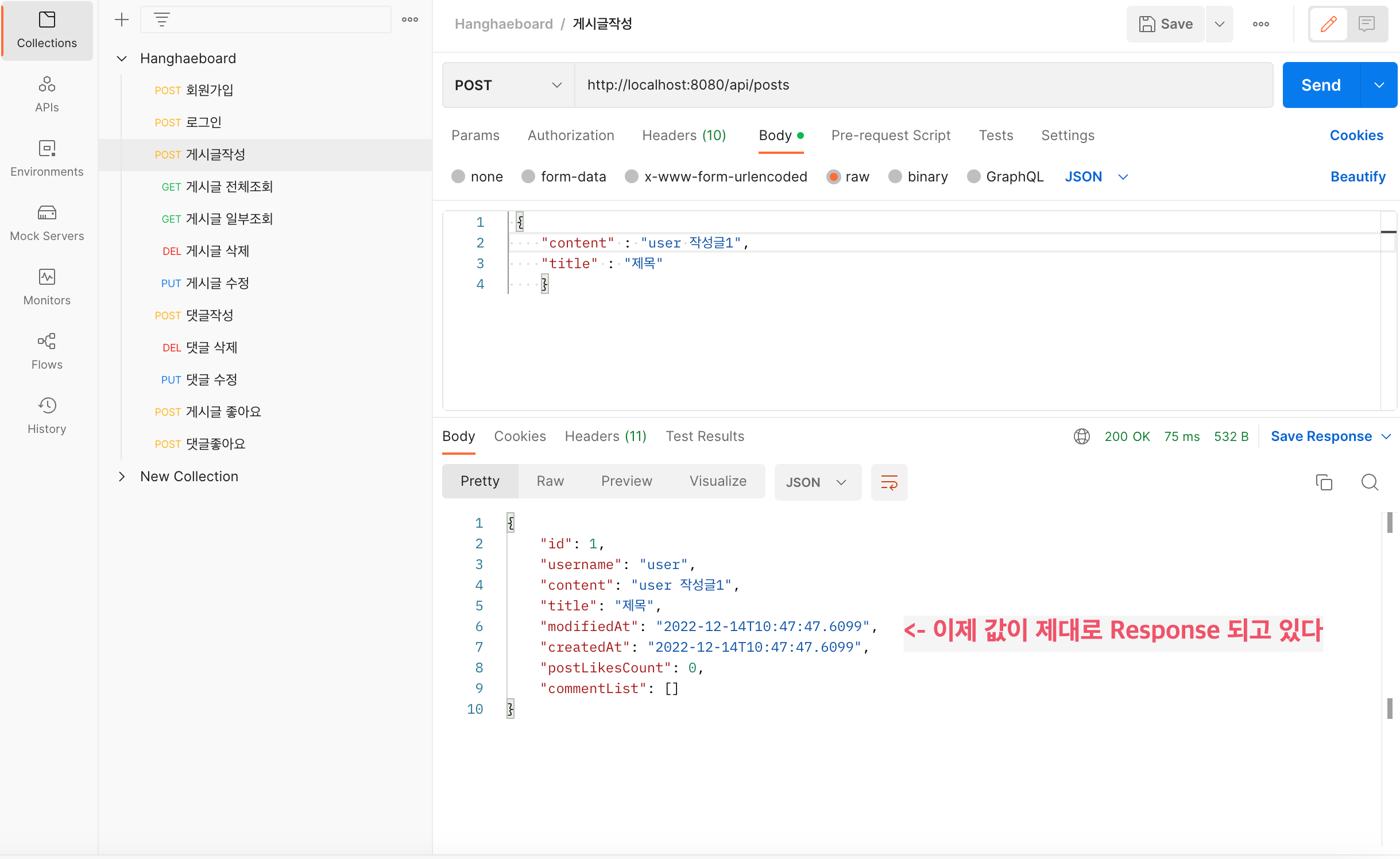
위와 같이 게시글을 입력하고 조회했을 때, 수정시간과 작성시간의 값이 null로 뜨는 문제가 발생했다.
2. 발생 이유
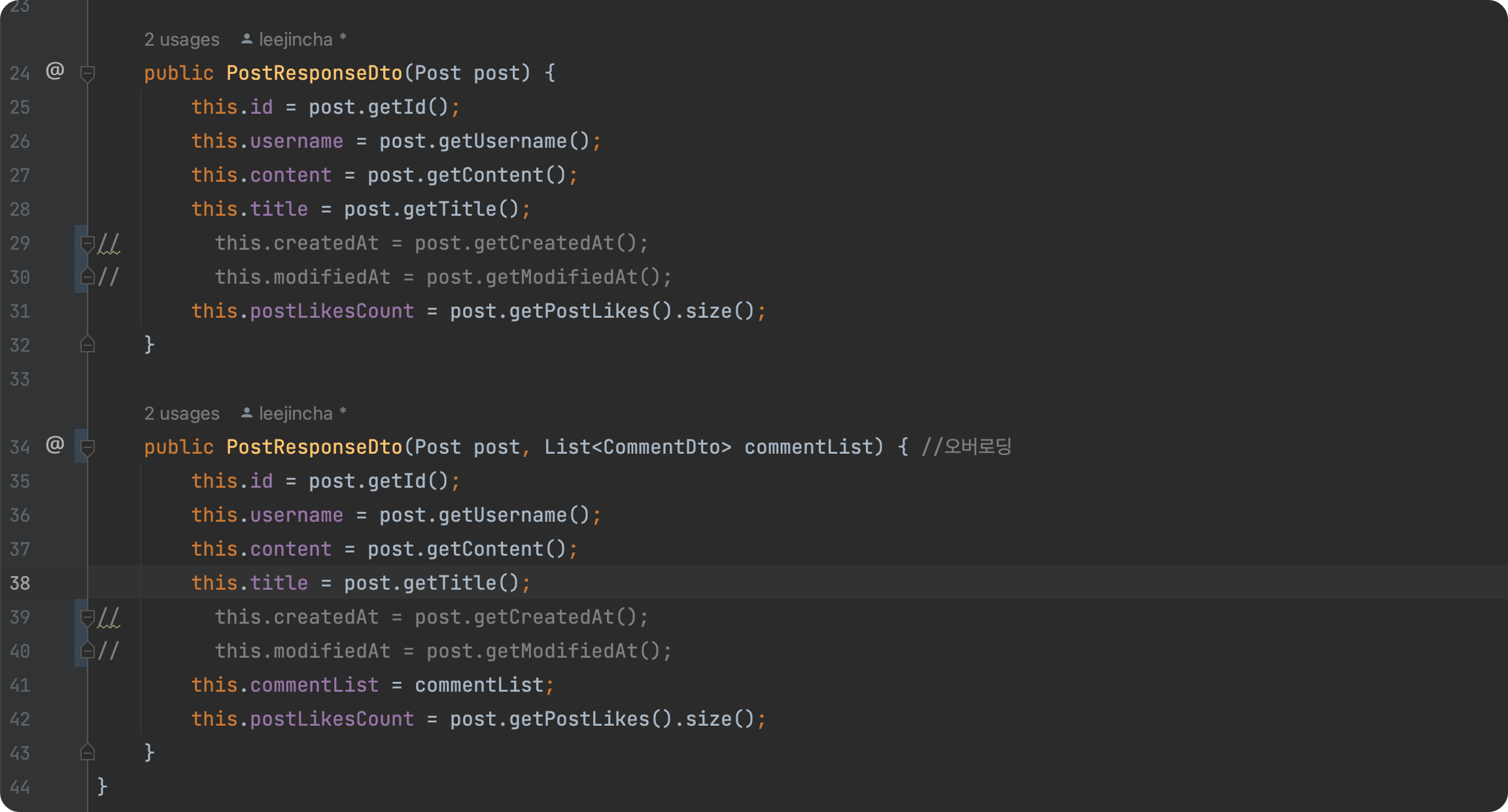
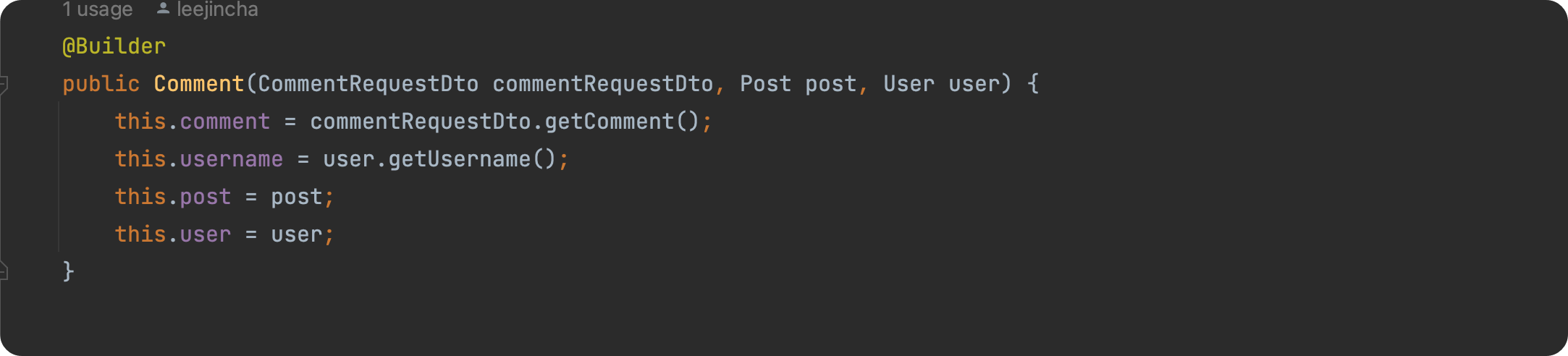
위는 ResponseDto 클래스 생성자 부분이다.
null값이 뜰 때는 주석처리되어 있는 부분을 작성하지 않은 상태였기 때문에 생성자 초기화가 되어있지 않은 상태인게 문제의 이유였다.
3. 해결
주석처리 했던 부분을 기입했더니 아래와 같이 값이 잘 들어오는 것을 확인할 수 있었다.
같은 조의 미경님도 PostMan으로 게시글 조회부분을 확인하실 때 id값이 들어오지 않는 문제가 있으셨는데, 나와 같은 이유로 Dto부분 생성자 부분에 id 값을 넣어주지 않아서 발생한 문제였다.
처음에 스프링에 대한 이해가 부족하다 보니, Entity와 Dto 두 가지 차이에 대한 이해가 부족해서 발생한 문제였다.
Entity는 DB에 저장되어지는 테이블 값이라고 생각하면 되고, Dto는 내가 원하는 값만 cutomize 해서 request를 받거나 response를 주는 부분이라고 생각하면 쉬울 것 같다.
따라서 Entity 처럼 모든 항목을 기입할 필요 없이, 게시글을 받는 부분의 RequestDto 부분의 생성자 부분엔 유저로 부터 입력값을 받게될 username, title, content 부분만 넣어주면 되고, 또 화면단으로 반환되는 부분은 ResponseDto 생성자 부분에 password를 제외한 id, username, title, content, modifiedAt, createdAt 등의 값들을 생성자 부분에 넣어주면 된다.
2. 순환참조 오류
1. 이슈
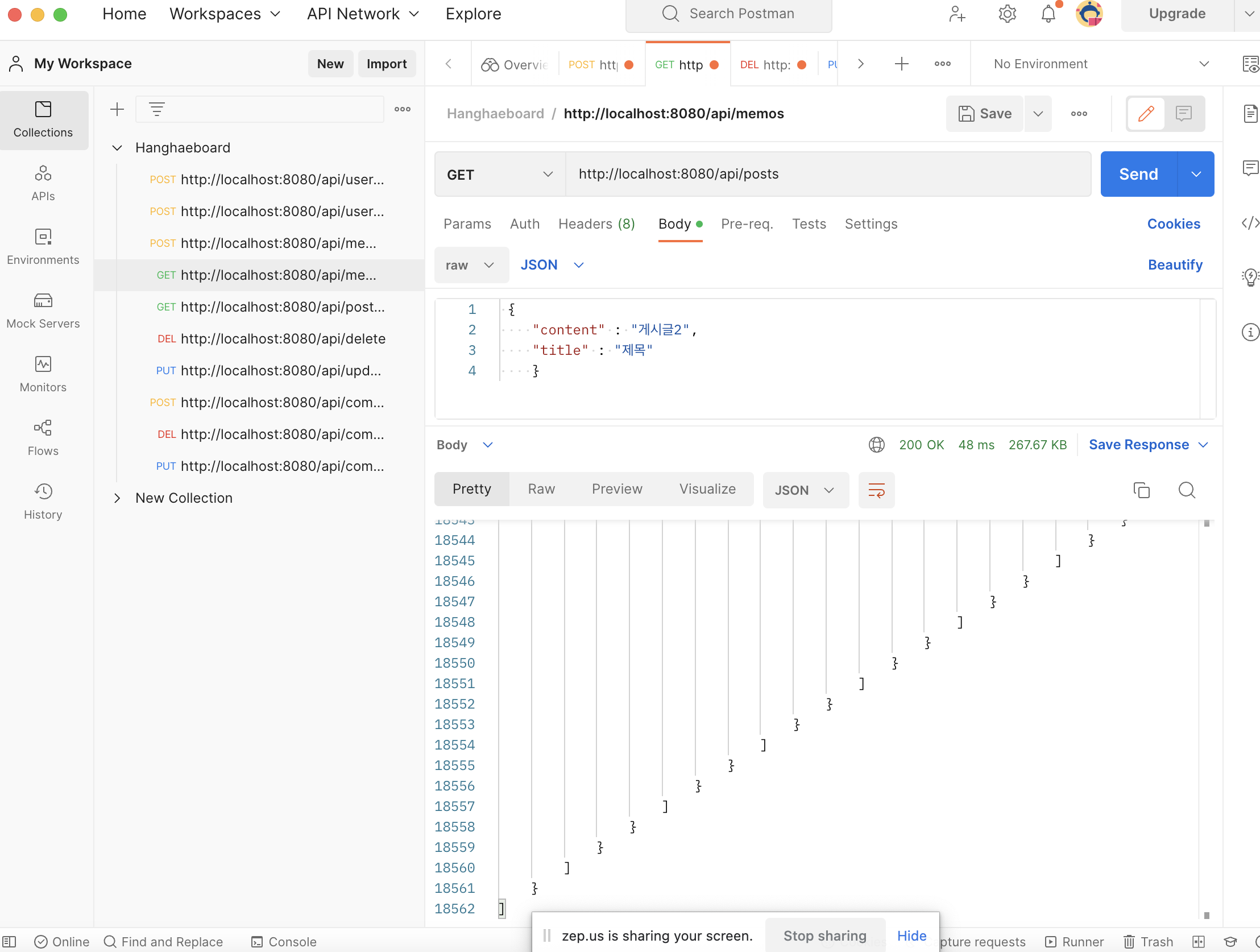
Post와 Comment를 각각 @OneToMany, @MantToOne 로 양방향 연관관계를 맺어주고 PostMan에서 게시글 조회를 했더니 순환참조오류인 Stack over flow 문제가 발생했다.
보이는 바와 같이 18,562 줄이나 조회가 되었음을 볼 수 있다.
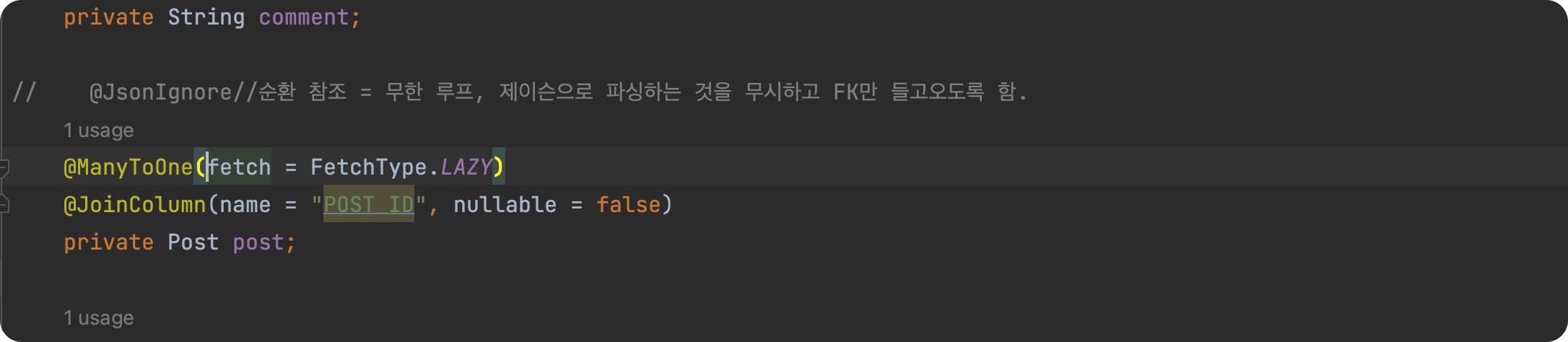
Comment EntityPost Entity
위와 같이 Post Entity 와 Comment Entity 부분에 양방향으로 연관관계가 맺어져 있다.
Comment Entity
2. 발생이유
그리고 위와 같이 Comment Entity 자체에 post 값이 들어가 있는데,
게시글을 조회하는 과정에서 그 밑에 연관관계로 맺어진 Comment List가 딸려오고,
그 딸려온 Comment 안에 또 모든 post값이 들어가기 때문에 돌고 돌아버리는 순환참조 오류가 발생한 것이다.
3. 해결 방법 (2 가지)
3-1. @JsonIgnore을 사용한다.
Post Entity 부분
당장의 순환참조 오류는 해결했지만, 완전한 방법은 아니다.
임시방편이라고 할 수있다.
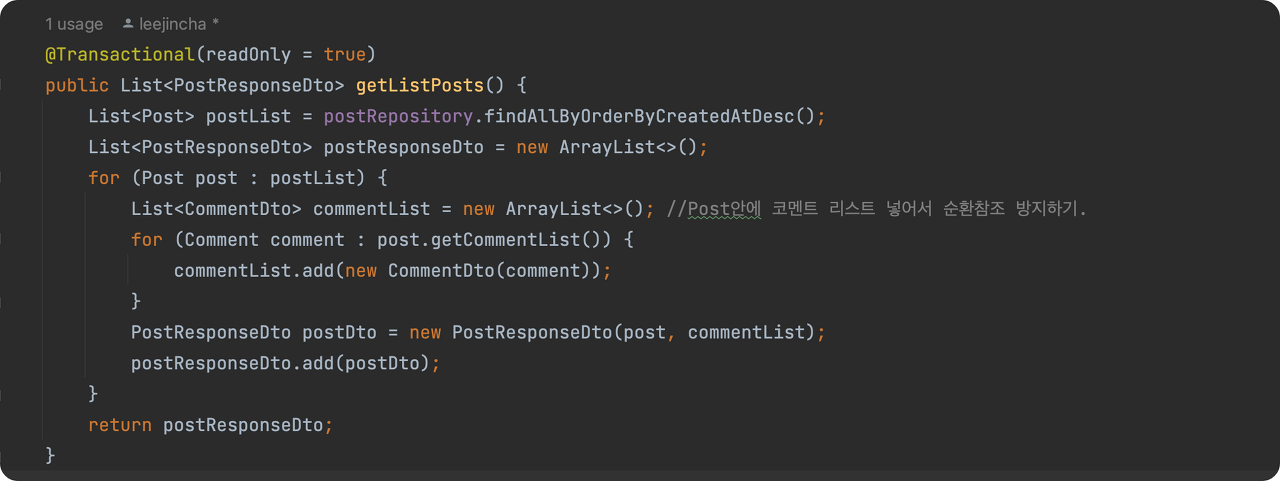
3-2. Dto부분의 설계를 잘 한다.
PostResponseDto 부분
List<> 안의 제네릭 부분을 Comment 엔티티로 하지 말고 Dto로 변환한뒤, 다시 배열을 만들어 Comment(Response)Dto 값들을 넣어준다.
배열을 변환해주는 과정은 Dto 혹은 Service단 모두 가능하지만, 일단 아래와 같이 Service 단에서 실행해 주었다.
PostService 게시물 전체조회 부분
이중 for each 반복문으로 CommentDto의 값이 들어간 commentList를 만들어 주고, 다시 그 댓글 리스트를 게시글 리스트에 넣어주었다.
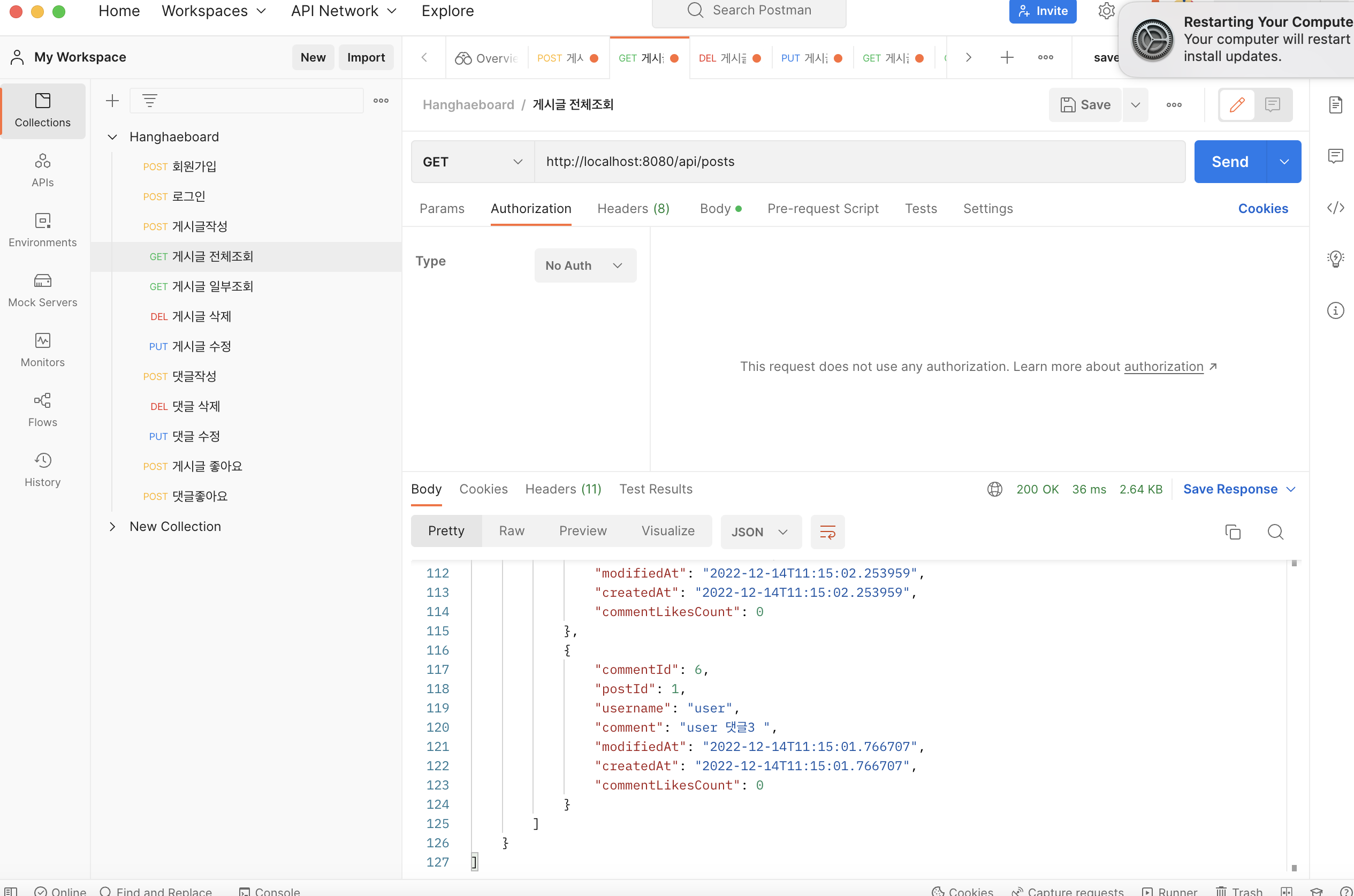
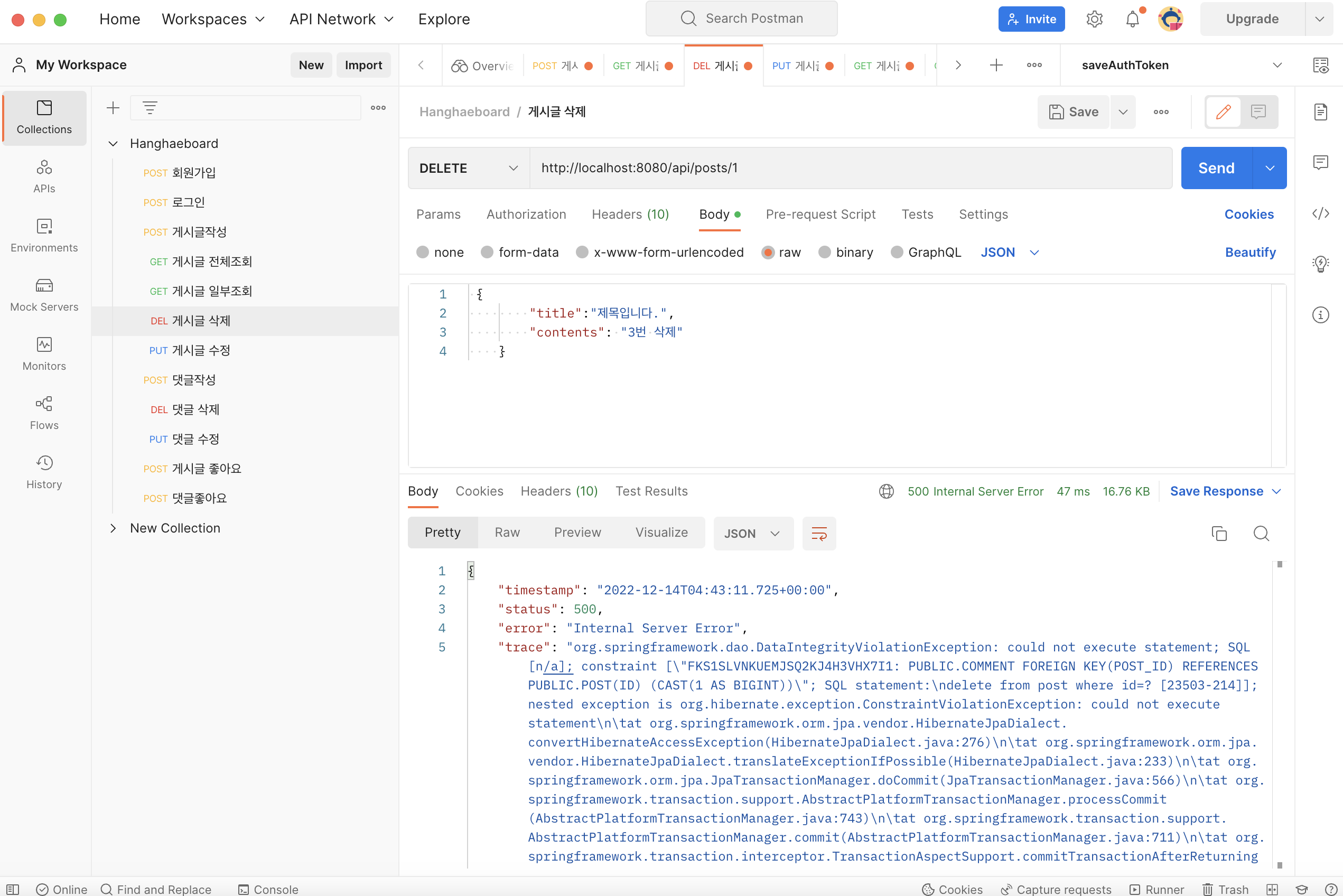
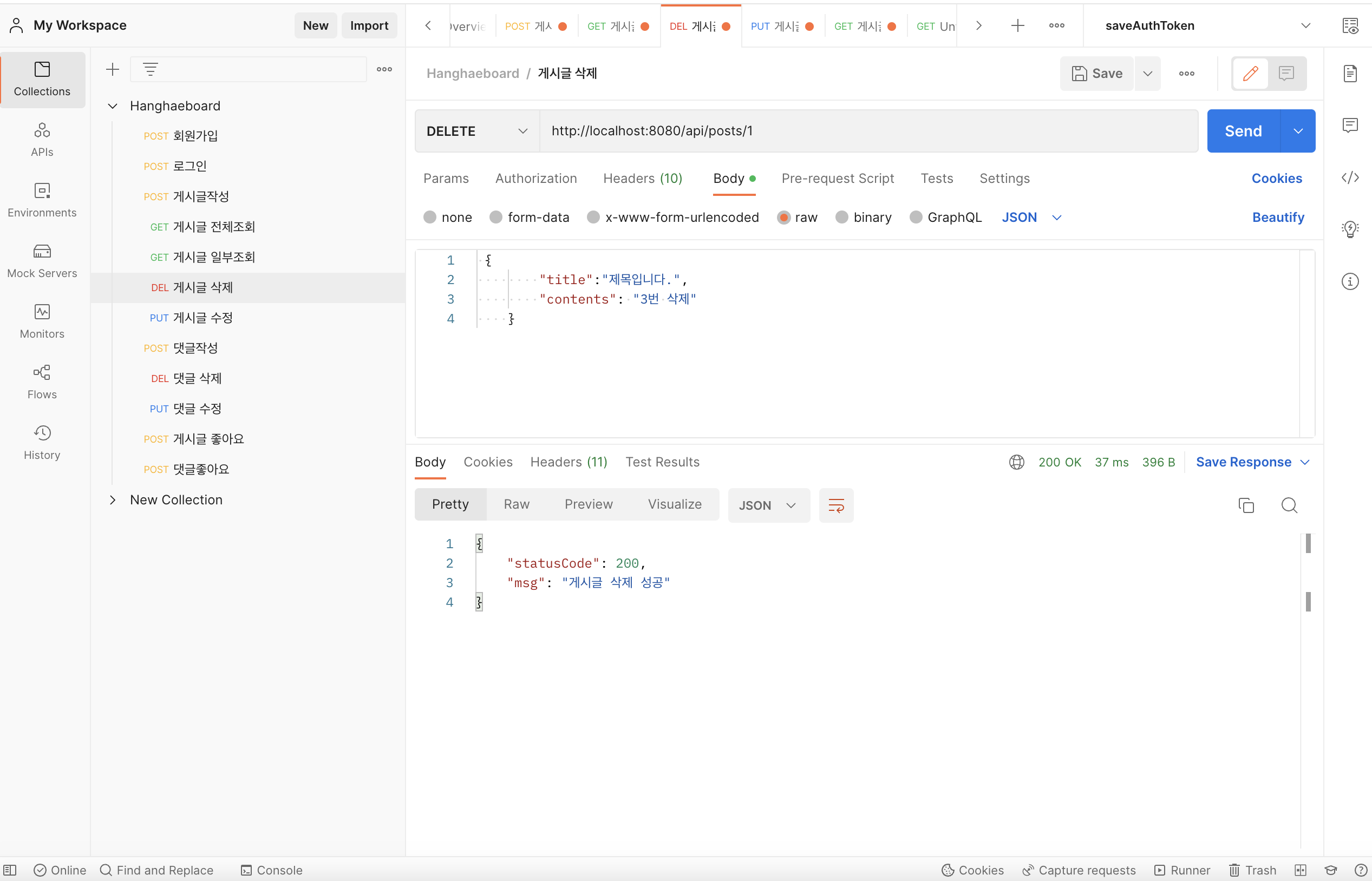
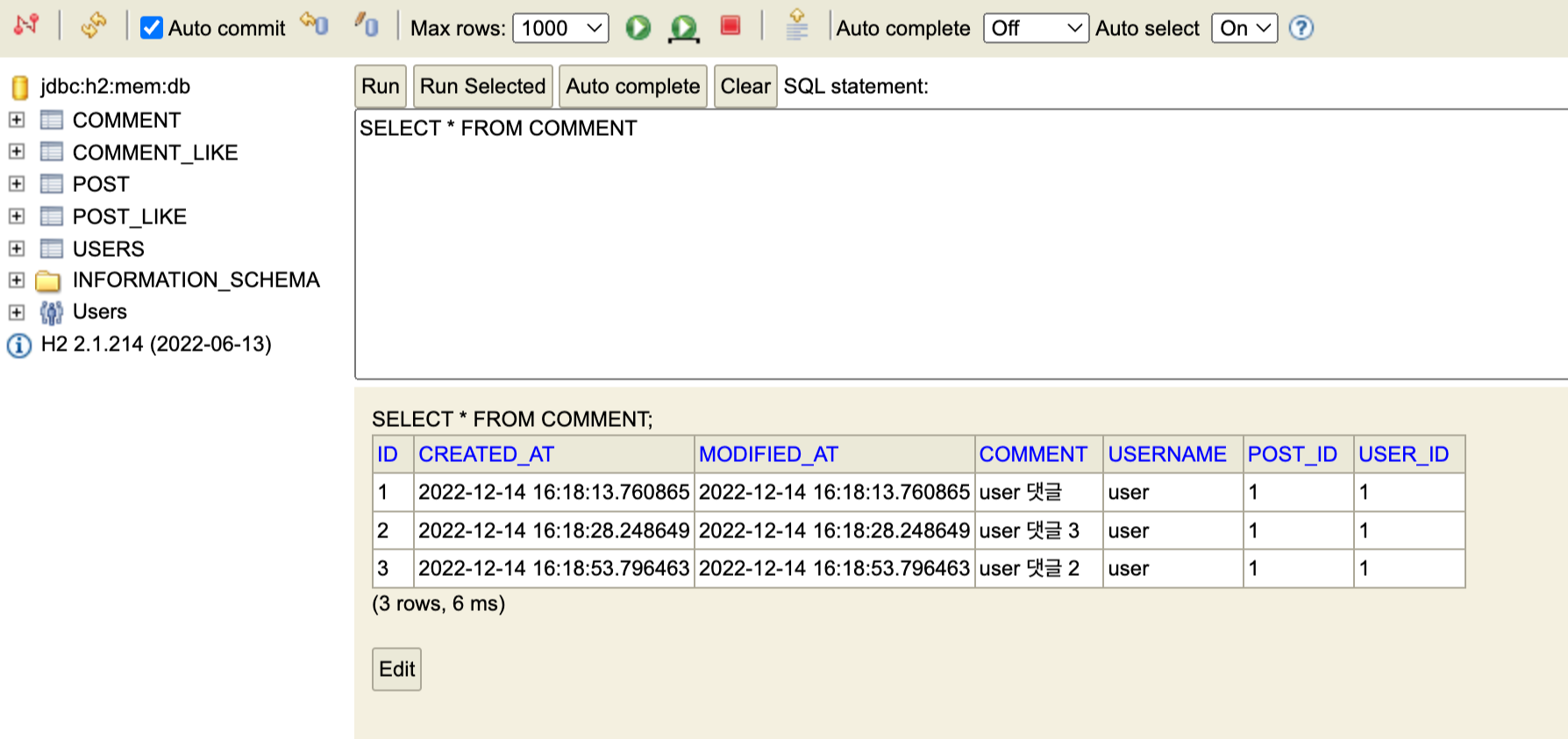
게시글 댓글 수정이 PostMan response 부분에 문제없이 처리가 되었다고 뜨는데, h2 콘솔 데이터베이스를 확인하면 데이터 변환이 일어나지 않음.
Comment Service 파일
PostMan에는 수정사항이 잘 반영되었다.h2-console
그러나 h2-console 에는 수정이 반영되지 않았다.
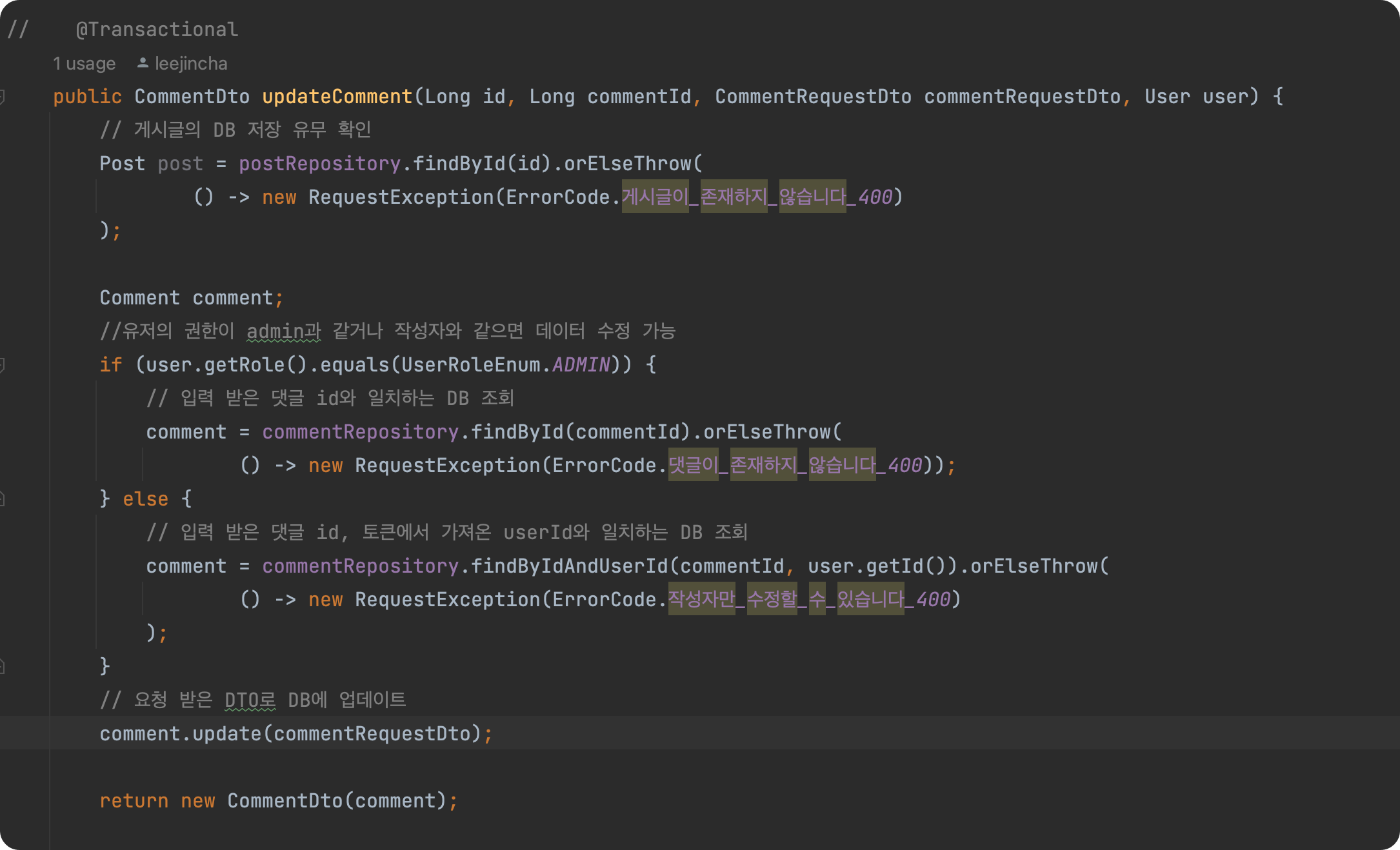
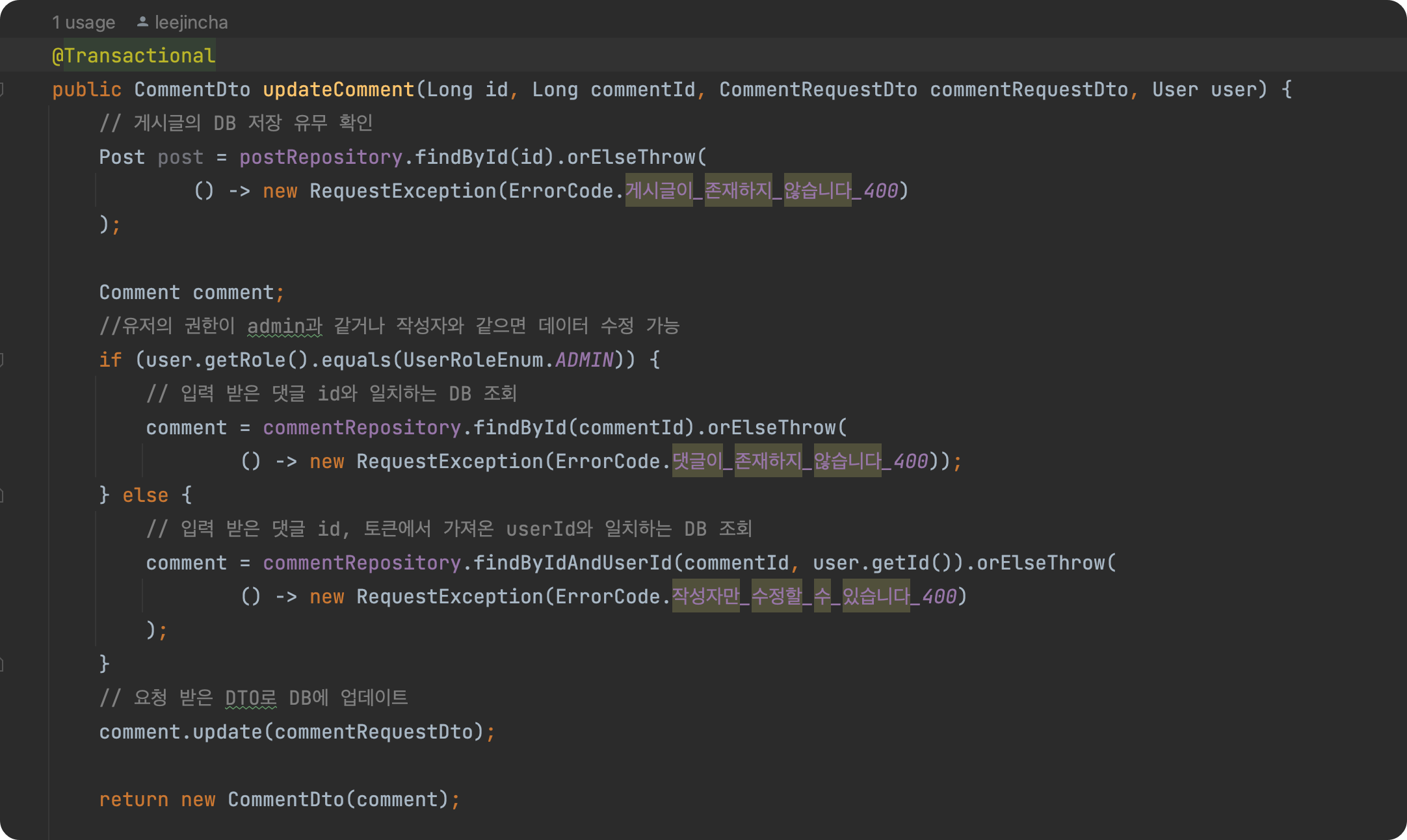
2. 발생 이유
update 메소드에 @Transattilnal 어노테이션이 빠졌다.
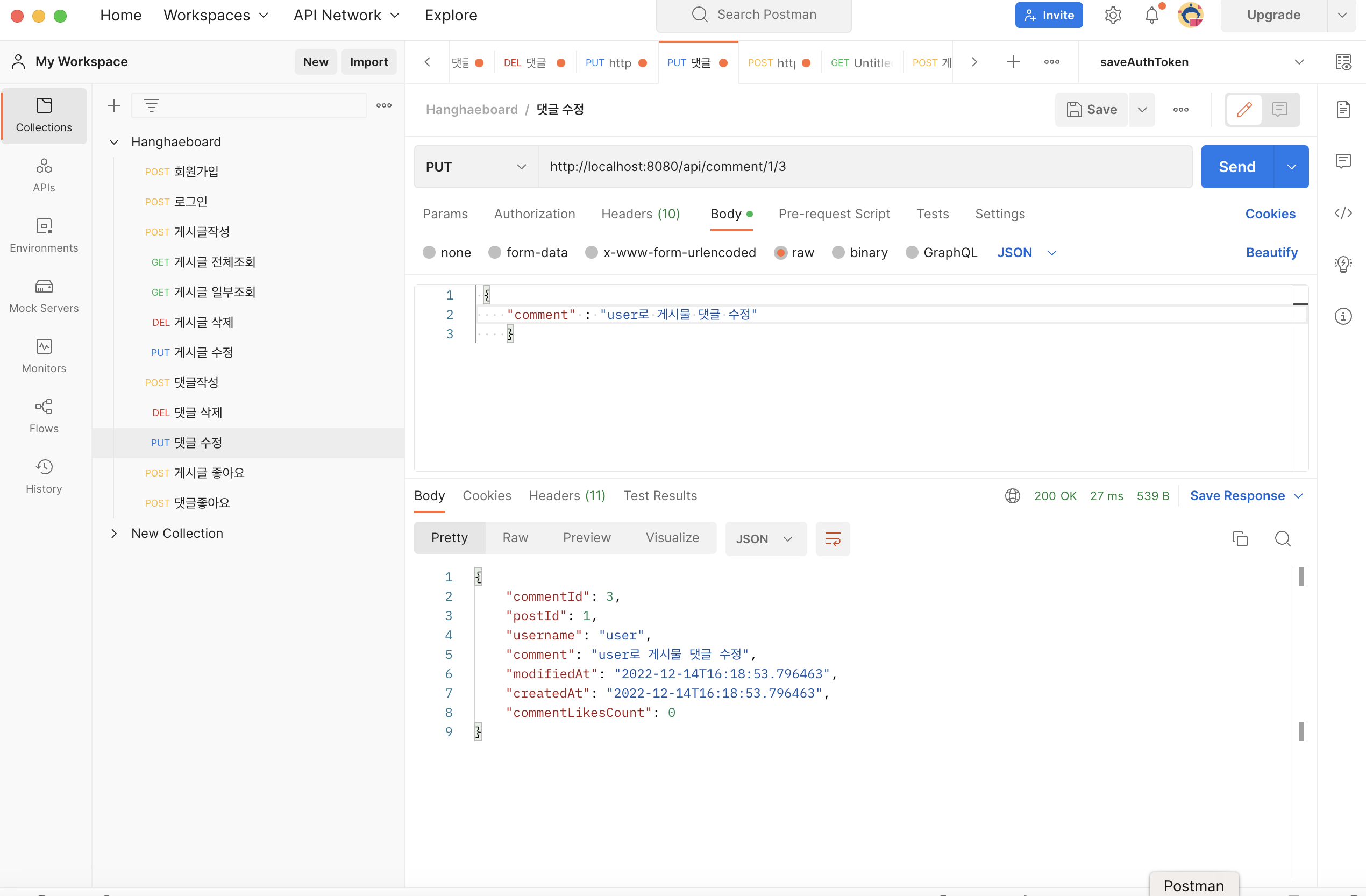
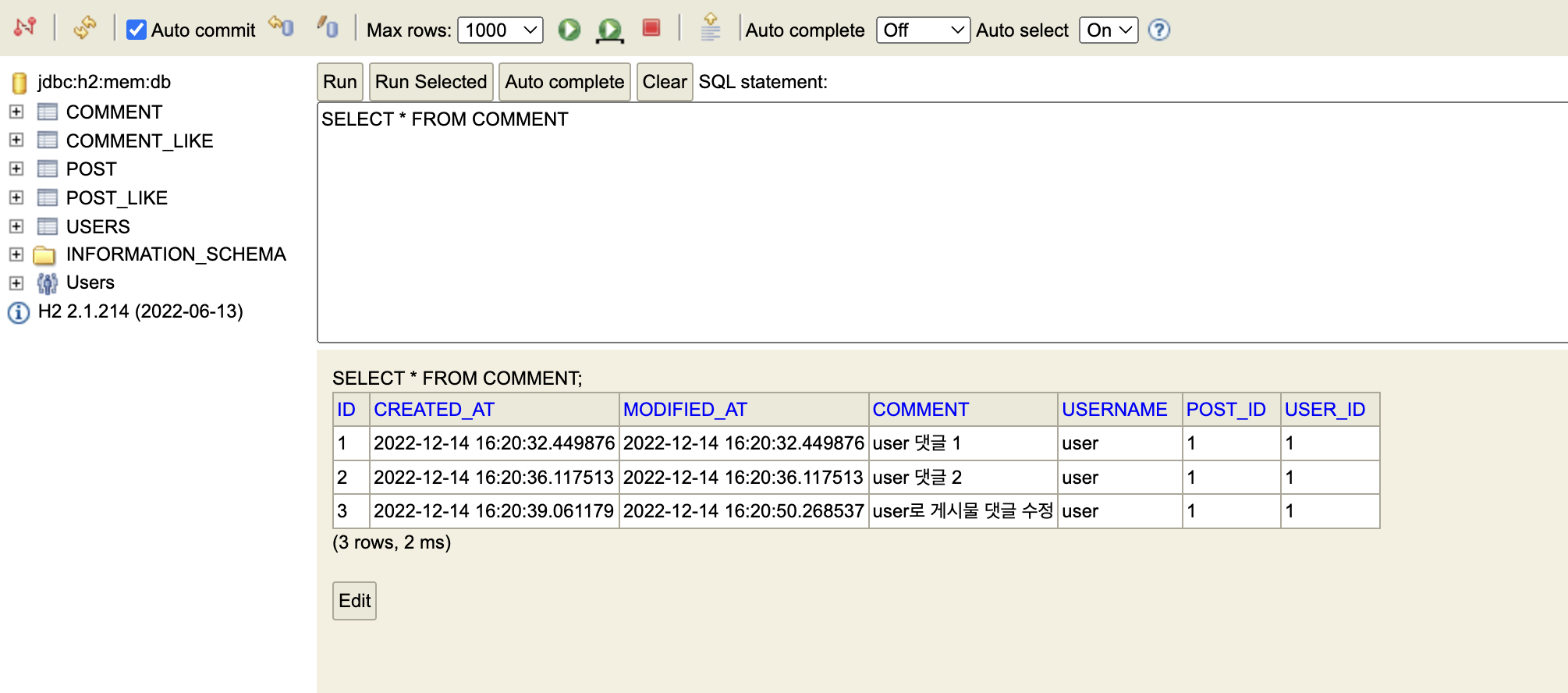
Comment Service update 부분수정 후 h2-console
3. 해결방법 : update 메소드에 @Transattilnal 어노테이션 추가
위와 같이 정상적으로 업데이트가 되는 것을 확인 할 수 있다. -> 이부분은 스프링 트랜스잭션 개념으로 다시 정리 할 것 ! :)
+ 이번 과제 관련 추가 (발생 가능성이 있었던 문제)
① N+1 문제
연관 관계에서 발생하는 이슈로 연관 관계가 설정된 엔티티를 조회할 경우에 조회된 데이터 갯수(n) 만큼 연관관계의 조회 쿼리가 추가로 발생하여 데이터를 읽어오게 된다. 이를 N+1 문제라고 한다.
N+1은 JPA를 사용하면서 연관관계를 맺는 엔티티를 사용한다면 한번 쯤은 부딪힐 수 있는 문제이다.
Fetch Join이나 EntityGraph를 사용한다면 Join문을 이용하여 하나의 쿼리로 해결할 수 있지만 중복 데이터 관리가 필요하고 FetchType을 어떻게 사용할지에 따라 달라질 수 있다.
SUBSELECT는 두번의 쿼리로 실행되지만 FethType을 EAGER로 설정해두어야 한다는 단점이 있다.
BatchSize는 연관관계의 데이터 사이즈를 정확하게 알 수 있다면 최적화할 수 있는 size를 구할 수 있겠지만 사실상 연관 관계 데이터의 최적화 데이터 사이즈를 알기는 쉽지 않다.
JPA 만으로는 실제 비즈니스 로직을 모두 구현하기 부족할 수 있다. JPA는 만능이 아니다. 간단한 구현은 JPA를 사용하여 프로젝트의 퍼포먼스를 향상 시킬수 있겠지만 다양한 비즈니스 로직을 복잡한 쿼리를 통해서 구현하다보면 다양한 난관에 부딪힐 수 있다. 그리고 불필요한 쿼리도 항상 조심해야 한다. 그러므로 QueryBuilder를 함께 사용하는 것을 추천한다. 그러면 생각보다 다양한 이슈를 큰 고민없이 바로 해결할 수 있다.
다대일 연관관계에서@JoinColumn(name)옵션은 컬럼 이름 매핑에 사용되는 어노테이션이지, 연관관계에는 아무런 영향이 없다. 단, 조인 대상 컬럼을 변경하기 위해@JoinColumn(referencedColumnName)어노테이션을 활용할 수 있다! 그러니 무조건적으로@JoinColumn을 생략해선 안되겠다.
다대일 연관관계 매핑에서만 그렇다. 일대다 단방향 연관관계 매핑에서는 @JoinColumn 어노테이션을 꼭 명시해주어야 한다. 그렇지 않을 경우 중간 테이블을 자동으로 생성한다. 또, 일대다 양방향 연관관계를 매핑하는 방식에서도 연관관계의 주인을 일(1)에게 주려 하는 경우 다(N) 쪽에 @JoinColumn(insertable = false, updatable = false)를 사용하면서 연관관계의 주인을 강제시키는 방법으로도 사용할 수 있다.
즉, 정리하자면@JoinColumn어노테이션은 원래 여러가지 옵션을 제공하고 할 수 있는 일이 많다. 그러나 다대일 연관관계 매핑에서는 JPA가 기본적으로 취하는 전략들이 있기 때문에,@JoinColumn어노테이션을 생략해도 기대하는 대로 동작한다.