① Inline Style Sheet : HTML 태그의 style 속성에 CSS 코드를 넣는 방법
<p style="color: blue">Lorem ipsum dolor.</p>
해당 태그(위 코드에서는 p)가 선택자(selector)가 되고, CSS 코드에는 속성(property)과 값(value)만 들어감. 따라서 꾸미는 데 한계가 있으며, 재사용이 불가능하다는 단점이 있다.
② Internal Style Sheet : HTML 문서 안의안에 CSS 코드를 넣는 방법
<style>
h1 {
color: blue;
}
</style>
<style> 태그는 보통 <head>와 </head> 사이에 넣으나, HTML 문서의 어디에 넣어도 잘 적용된다. 이 방법은 HTML 문서 안의 여러 요소를 한번에 꾸밀 수 있다는 장점이 있으나, 또 다른 HTML 문서에는 적용할 수 없다는 단점이 있다.
③ Linking Style Sheet : 별도의 CSS 파일을 만들고 HTML 문서와 연결하는 방법
적용을 원하는 HTML 문서에 다음의 코드를 추가
<link rel="stylesheet" href="style.css">
위 코드는 HTML 파일과 CSS 파일이 같은 폴더에 있다고 가정했을 때의 코드로, 경로는 적절히 수정해야 한다. 예를 들어 HTML 문서가 있는 폴더에 css 폴더가 있고, 그 안에 style.css 파일이 있다면 다음과 같이 해준다.
<link rel="stylesheet" href="css/style.css">
이 방법의 장점은 여러 HTML 문서에 사용할 수 있다는 것. style.css를 적용시키고 싶은 문서에 <link> 태그로 연결만 해주면 된다.
2) CSS Basic Grammer
h1 {
color: red;
/*font-size: 20px;*/
}
① 선택자(selector) : 무엇을 꾸밀지 정한다. h1은 h1 요소를 꾸미겠다는 뜻
② 속성(property) : 어떤 모양을 꾸밀지 정한다. color는 색을 꾸미겠다는 뜻
③ 값(value) : 어떻게 꾸밀지 정한다. red는 빨간색으로 만들겠다는 뜻
④ 주석(Comment)은 /*과 */ 사이에 쓴다.
※ 세미콜론(;)으로 구분하여 선언을 여러 개 넣을 수 있다.
4) CSS Selectors
① 전체 선택자(Universal Selector) : 모든 HTML 요소를 선택합니다. 별표(*)로 나타냄
② 아이디 선택자(ID Selector) : 특정 값을 id 속성(attribute)의 값으로 갖는 요소(element)를 선택. 속성값 앞에 #을 붙여 아이디임을 나타냄
③ 클래스 선택자(Class Selector) : 특정 값을 class 속성(attribute)의 값으로 갖는 요소(element)를 선택. 속성값 앞에 .을 붙여 클래스임을 나타냄.
④ 타입 선택자(Type Selector) : h1, p, div, span 등 HTML 요소(Element)를 선택하는 선택자
<속성에 따른 우선순위 정리>
속성 값 뒤에 !important 를 붙인 속성 ex. .mytitle { color : black !important ; }
HTML에서 style을 직접 지정한 속성 ex. <h1 style = “color : white”>(head에 있는 style이 아니라 body에 있는 특정 코드에 style을 직접 적용)
#id 로 지정한 속성
클래스,추상클래스로 지정한 속성 ex. .mytitle : hover {___}
태그이름 으로 지정한 속성 ex. .h1 { color : red ; }
상위 객체에 의해 상속된 속성 (부모-자식 구조)
그렇기 때문에 CSS에선 선택자(selector)와 선언부(declaration)를 적절하게 잘 사용할 수 있어야 한다.
5) Box Model
색이 있는 모든 영역이 h1 요소. 각 색이 나타내는 영역은 다음과 같다.
① : 바깥 여백 영역(Margin Area)
② : 테두리 영역(Border Area)
③ : 안쪽 여백 영역(Padding Area)
④ : 내용 영역(Content Area)
각 영역을 꾸밀 때 사용하는 속성은 다음과 같다.
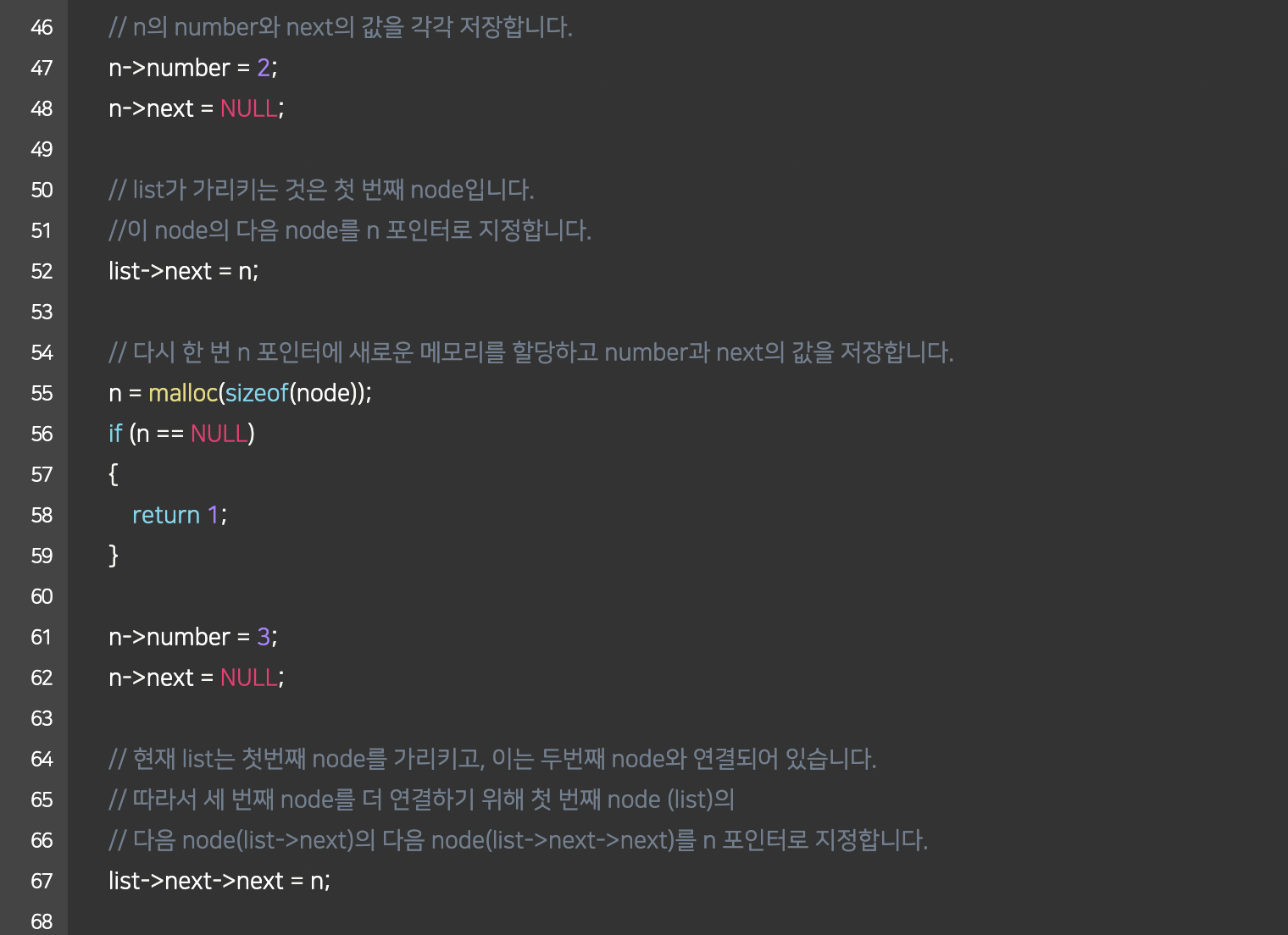
바깥 여백 : margin 속성
테두리 : border 속성
안쪽 여백 : padding 속성
박스의 가로 크기 : width 속성
박스의 세로 크기 : height 속성
박스의 크기 기준 : box-sizing 속성
박스의 배경 : background 속성
6) Grid
CSS Grid Layout excels at dividing a page into major regions or defining the relationship in terms of size, position, and layer, between parts of a control built from HTML primitives.
Like tables, grid layout enables an author to align elements into columns and rows.
However, many more layouts are either possible or easier with CSS grid than they were with tables.
For example, a grid container's child elements could position themselves
so they actually overlap and layer, similar to CSS positioned elements.
7) Media Queries
Media queries can be used to check many things, such as:
width and height of the viewport
width and height of the device
orientation (is the tablet/phone in landscape or portrait mode?)
resolution
Using media queries are a popular technique for delivering a tailored style sheet to desktops, laptops, tablets, and mobile phones (such as iPhone and Android phones).
저번주를 끝으로 다들 웹개발 종합반 강의를 2회차씩 돌렸기 때문에, 이번주 부터는 토이프로젝트에 관한 회의를 매일 진행하기로 했다.
오늘 대략적으로 토이프로젝트의 주제와, 틀, 그리고 구현할 기능들에 대해 이야기를 나누었다.
오늘 회의 내용을 대략적으로 정리해 보자면,
토이프로젝트 주제
코딩 관련된 유용한 소스(사이트 링크)를 모아 놓은 웹 페이지
글쓴이가 유튜브 링크를 가져와 추천하는 이유와 난이도 및 카테고리 등을 설정해서 등록
1차 구현 난이도
웹개발 종합반 강의와 비슷한 수준 + 크롤링 (가능하다면)
2차로 구현할 것
로그인과 회원가입에 난이도 있는 기술 넣기 + like(좋아요) 기능 (모아보기)
전체적인 플로우 구상
1. 메인페이지 (에서 로그인 박스를 만들어 놓고 클릭하기) 2. 로그인 페이지 (로그인 하면 (DB조회) -> 카테고리 페이지 이동 or 회원가입) 3. 회원가입 페이지 - DB 등록 (로그인 페이지와 회원가입 페이지는 두명이상 같이 맡아서 하기) 4. 카테고리페이지 (카톡 선물하기 페이지같은 느낌) 5. 카테고리에 맞는 list페이지[GET]요청 /DB 조회 (스파르타피디아와 비슷한 느낌으로 - 썸네일, 제목, 난이도 별, 카테고리) + 기록 [POST]요청 /DB등록 -> 세부페이지는 같은 양식의 페이지를 html/css로 만들어 놓고 사용 6. list페이지 클릭하면 세부페이지 나오기 [GET]요청 /DB 조회
1. 메인페이지를 없앤다면 로그인페이지로 시작하고, 세부페이지를 좀 더 만들어보기 2. 세부페이지를 list페이지와 묶는다면 메인페이지로 시작하기.
다음 회의 전까지 해야할 일
로그인과 회원가입 구현방식 알아보기 + 유튜브링크 크롤링 방법 알아보기
이정도인 것 같다.
지난번 미팅 스몰토크 때 토이프로젝트와 관련하여 등록한 사람별로 sorting 해서 페이지를 만들어보자는 의견이 있었는데
내 생각엔 카테고리 별로( 예를 들면, 자바스크립트/리액트, 자바/스프링, html/css) 페이지를 만드는 게 더 좋을 것 같아서 의견을 냈고, 모두 동의해 주셨다.
그리고 소영님이 코딩과 관련된 웹페이지 제작 아이디어와 회원가입 관련 jwt 아이디어를 주셨고,
현빈님은 큰 플로우흐름을 한 번 정리해주시고 와이어프레임을 내일까지 만들어 주시기로 하셨다.
미경님은 아직 일을 하고 계셔서 바쁘신데도 불구하고 게더와 사전스터디 노션 페이지를 제작해 주셔서 덕분에 너무 잘 이용하고 있다.
민승님은 팀원들이 제안하는 의견을 조용하지만 묵직하게 뒤에서 열심히 공부해주는 분인 것 같다. 그리고 좋은 사이트 (알고리즘 테스트) 같은 것도 공유해 주신다.
팀원분들에 비해 너무 부족한 실력이라 따라가기에 급급하지만, 그래도 팀원분들을 보면서 많이 배우는 중이다. 특히 지난주엔 게더를 켜놓고 공부를 했는데, 혼자 하는 기분이 아니라 괜히 자극도 되고 위안도 되서 앞으로도 게더를 잘 활용해야 겠다고 생각했다. 아직 부트캠프가 시작도 하지 않았지만, 혼자였으면 준비하지 못했을 것들을 팀을 통해 부족하지만 그나마 차근히 준비할 수 있는 것 같아서 좋다.