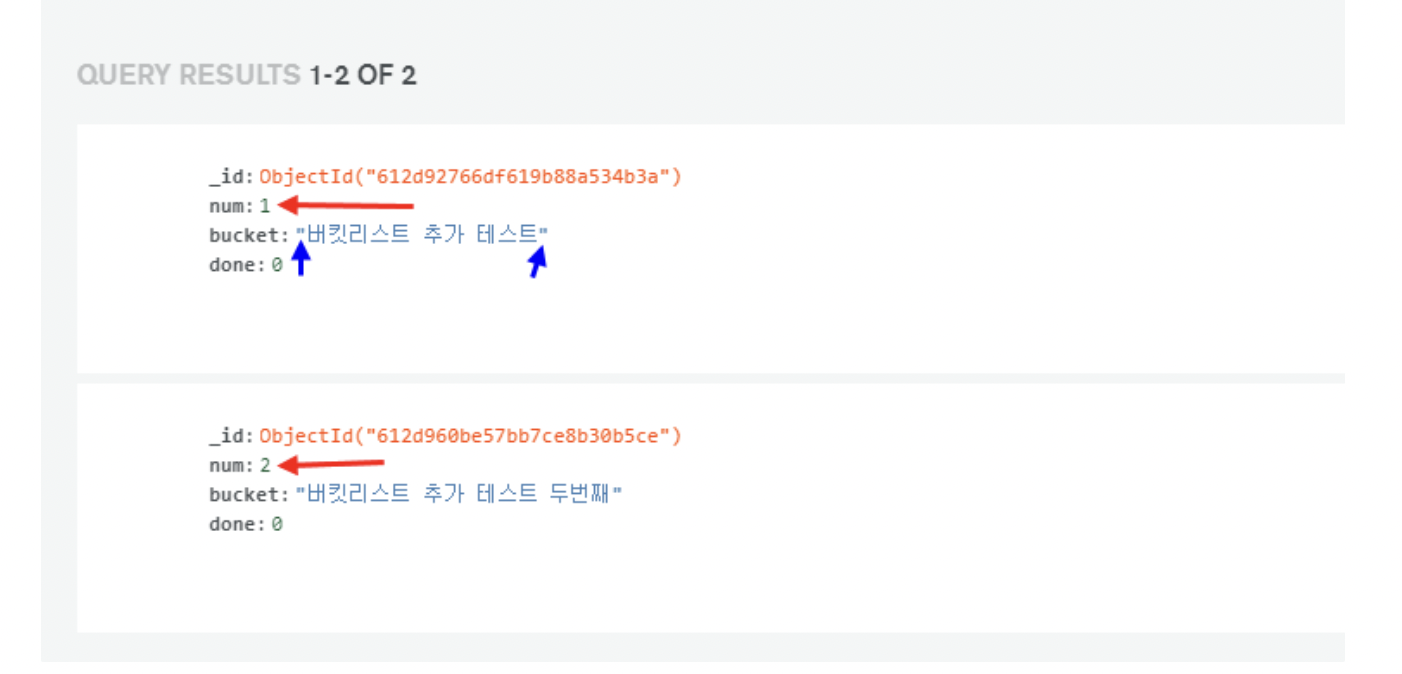
저번주를 끝으로 다들 웹개발 종합반 강의를 2회차씩 돌렸기 때문에, 이번주 부터는 토이프로젝트에 관한 회의를 매일 진행하기로 했다.
오늘 대략적으로 토이프로젝트의 주제와, 틀, 그리고 구현할 기능들에 대해 이야기를 나누었다.
오늘 회의 내용을 대략적으로 정리해 보자면,
토이프로젝트 주제
코딩 관련된 유용한 소스(사이트 링크)를 모아 놓은 웹 페이지
글쓴이가 유튜브 링크를 가져와 추천하는 이유와 난이도 및 카테고리 등을 설정해서 등록
1차 구현 난이도
웹개발 종합반 강의와 비슷한 수준 + 크롤링 (가능하다면)
2차로 구현할 것
로그인과 회원가입에 난이도 있는 기술 넣기 + like(좋아요) 기능 (모아보기)
전체적인 플로우 구상
1. 메인페이지 (에서 로그인 박스를 만들어 놓고 클릭하기) 2. 로그인 페이지 (로그인 하면 (DB조회) -> 카테고리 페이지 이동 or 회원가입) 3. 회원가입 페이지 - DB 등록 (로그인 페이지와 회원가입 페이지는 두명이상 같이 맡아서 하기) 4. 카테고리페이지 (카톡 선물하기 페이지같은 느낌) 5. 카테고리에 맞는 list페이지[GET]요청 /DB 조회 (스파르타피디아와 비슷한 느낌으로 - 썸네일, 제목, 난이도 별, 카테고리) + 기록 [POST]요청 /DB등록 -> 세부페이지는 같은 양식의 페이지를 html/css로 만들어 놓고 사용 6. list페이지 클릭하면 세부페이지 나오기 [GET]요청 /DB 조회
1. 메인페이지를 없앤다면 로그인페이지로 시작하고, 세부페이지를 좀 더 만들어보기 2. 세부페이지를 list페이지와 묶는다면 메인페이지로 시작하기.
다음 회의 전까지 해야할 일
로그인과 회원가입 구현방식 알아보기 + 유튜브링크 크롤링 방법 알아보기
이정도인 것 같다.
지난번 미팅 스몰토크 때 토이프로젝트와 관련하여 등록한 사람별로 sorting 해서 페이지를 만들어보자는 의견이 있었는데
내 생각엔 카테고리 별로( 예를 들면, 자바스크립트/리액트, 자바/스프링, html/css) 페이지를 만드는 게 더 좋을 것 같아서 의견을 냈고, 모두 동의해 주셨다.
그리고 소영님이 코딩과 관련된 웹페이지 제작 아이디어와 회원가입 관련 jwt 아이디어를 주셨고,
현빈님은 큰 플로우흐름을 한 번 정리해주시고 와이어프레임을 내일까지 만들어 주시기로 하셨다.
미경님은 아직 일을 하고 계셔서 바쁘신데도 불구하고 게더와 사전스터디 노션 페이지를 제작해 주셔서 덕분에 너무 잘 이용하고 있다.
민승님은 팀원들이 제안하는 의견을 조용하지만 묵직하게 뒤에서 열심히 공부해주는 분인 것 같다. 그리고 좋은 사이트 (알고리즘 테스트) 같은 것도 공유해 주신다.
팀원분들에 비해 너무 부족한 실력이라 따라가기에 급급하지만, 그래도 팀원분들을 보면서 많이 배우는 중이다. 특히 지난주엔 게더를 켜놓고 공부를 했는데, 혼자 하는 기분이 아니라 괜히 자극도 되고 위안도 되서 앞으로도 게더를 잘 활용해야 겠다고 생각했다. 아직 부트캠프가 시작도 하지 않았지만, 혼자였으면 준비하지 못했을 것들을 팀을 통해 부족하지만 그나마 차근히 준비할 수 있는 것 같아서 좋다.
이 글이 나와 같이 완전 제로베이스에 가장 기초라는 웹 개발 종합반을 수강하면서 본인의 부족함과 시작도 하지 않은 공부에 대한 막막함을 느낄 누군가에게 위로가 되길 바라며 적어보려 한다.
일단 웹개발 종합반이라는 강의는 항해99 부트캠프에 참여하려는 사람이라면 누구나 들어야 하는 사전과제이다. 나는 강의를 3번 돌리고 나서야 그나마 이 회고록을 작성할 수 있었다. 누군가에게는 너무나 쉬운 강의겠지만, 나처럼 아예 코딩이라는 것이 처음인 사람에게는 이마저도 한 번에 이해가 쉽지 않은 강의였다.
강의를 3번 돌렸다고 해서 아직 완전히 모든 부분이 이해되는 것은 아니다. 11월 9일에 부트캠프에 참가할 자격을 결정하는 사전시험이 있는데, 그것을 통과하려면 꼭 이해하고 넘어가야 하는 강의이기 때문에 아마 앞으로 최소 1번 혹은 두 번은 더 완강을 해야 그나마 80프로는 이해가 될 것 같다.
이렇게 코딩에 대해 아무것도 모르고 다른 사람에 비해 너무나 낮은 실력에 막막한 마음을 갖고 있는 사람이 여기도 있다. 그래도 강의를 듣기 전의 나와 지금의 나를 생각해 보면 분명히 많은 발전이 있다고 생각한다. 그러니 어쩌다 이 글을 보게 될 나와 같은 분도 끝까지 용기를 잃지 마시고! 의지를 잃지 마시고! 천천히 성장하는 개발자가 되셨으면 좋겠다.
이 부분이 가장 헷갈렸던 부분이다. 리눅스 언어를 이용하여 Terminal 창에 입력을 해서 진행시켜야 했는데, 이번이 세 번째 웹 배포다 보니까 뭔가 자꾸 오류가 생기고 할 때마다 헤매는 것 같다. 참고로 오늘 포스팅은 이미 모든 프로그램이 설치되어있고 배포가 되어있는 상태에서 하다 보니 생략된 부분이 많다. (예를 들면, 파이썬 설치 등..)
일단 내가 이해한 부분을 차래대로 정리해 보자면,
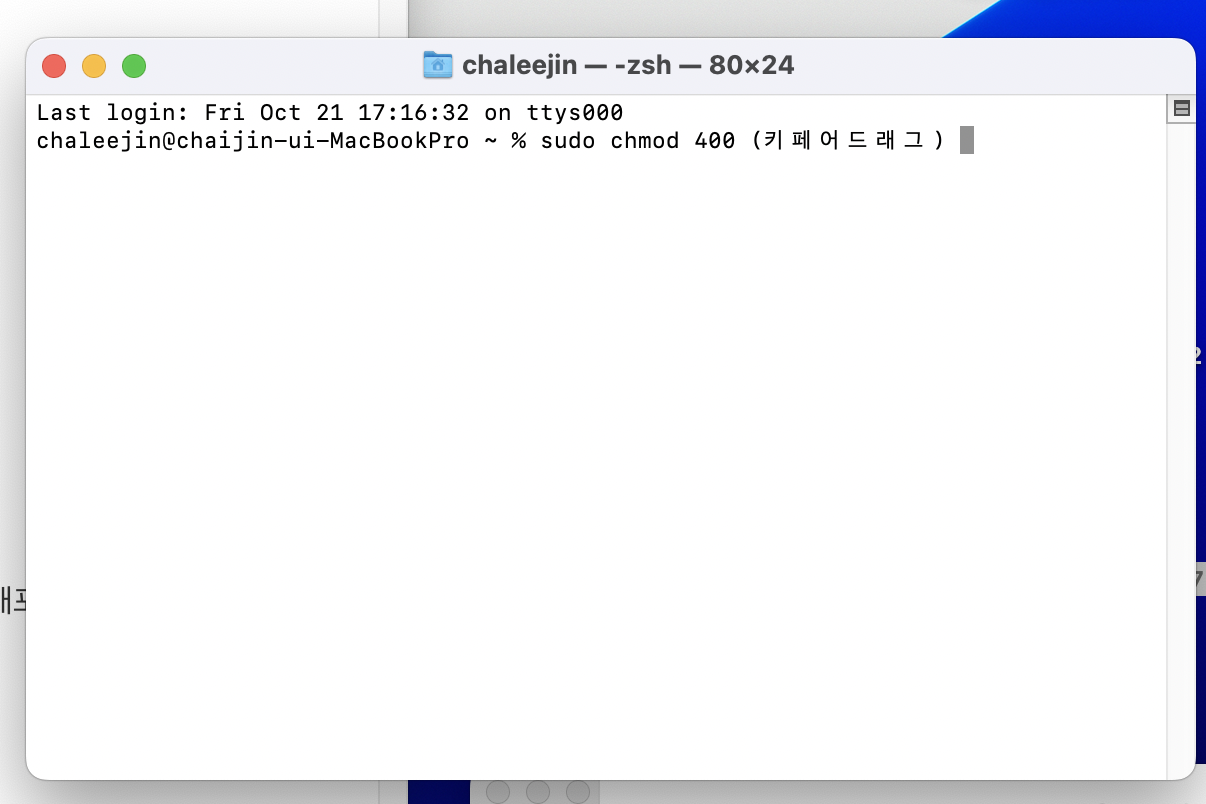
1. Mac 인 경우 Spotlight 검색을 켜고(오른쪽 상단 돋보기 모양 아이콘 클릭) Terminal을 검색 실행시켜준다.
2. Terminal 창이 뜨면, 다음과 같이 입력한다
sudo chmod 400 (여기엔 다운로드하였던 키페어 드래그해서 붙여 넣기) 그리고 엔터!
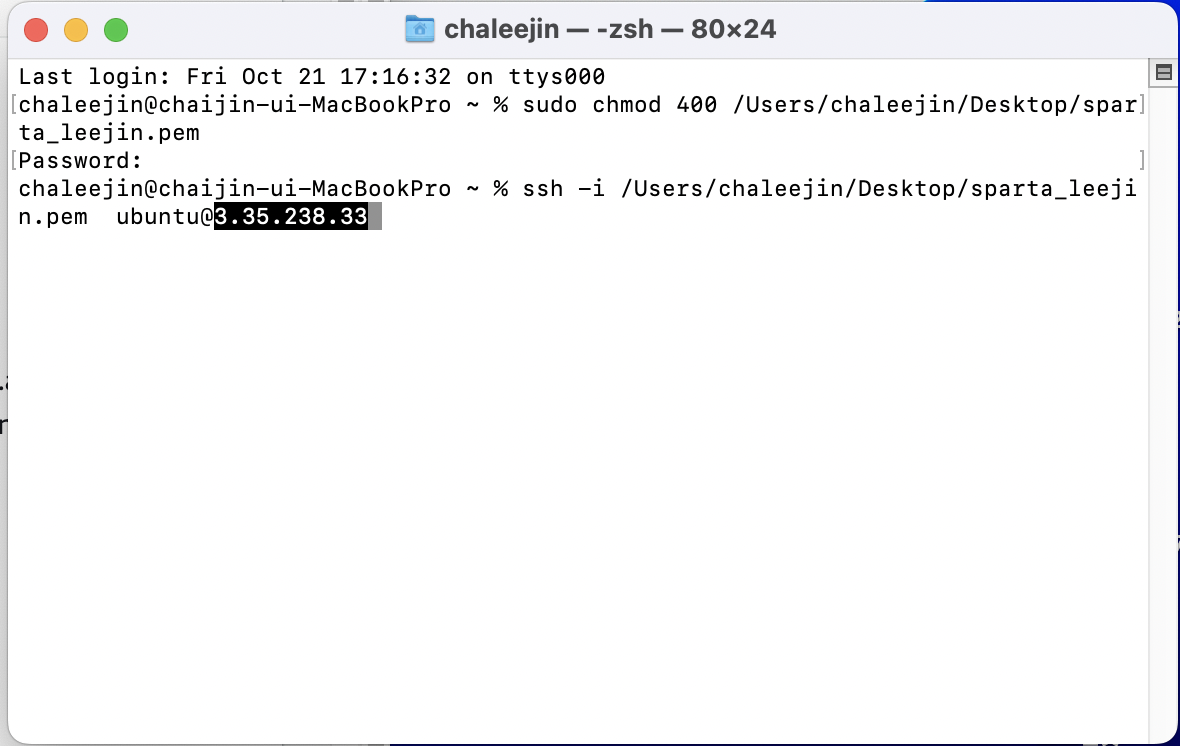
3. 다음과 같은 화면이 뜨면 맥북 개인 비밀번호를 입력하고 엔터!
4. ssh -i (다시 한번 키페어 드래그) ubuntu@(여기는 AWS 퍼블릭 주소 복붙) 엔터!
저기 퍼블릭 IPv4 주소 숫자부분을 복사해서 @뒤에 붙여주기
5. 중간 과정은 이미 내가 폴더를 만들어 놓고 배포한 상태라 스크린 샷이 없는데 mkdir spart을 입력해서 sparta 폴더를 생성해 준다. 참고로 mkdir 은 폴더를 생성하는 리눅스 언어인데 다음번에 리눅스 관련 언어 정리 포스트를 하면서 다시 정리하도록 하겠다.
6. 그런 다음 ls를 입력하면 아래와 같이 sparta 가 뜨는 것을 확인할 수 있다. ls는 현재 위치에서 디렉터리(폴더) 내용물을 보여주는 리눅스 명령어이다.
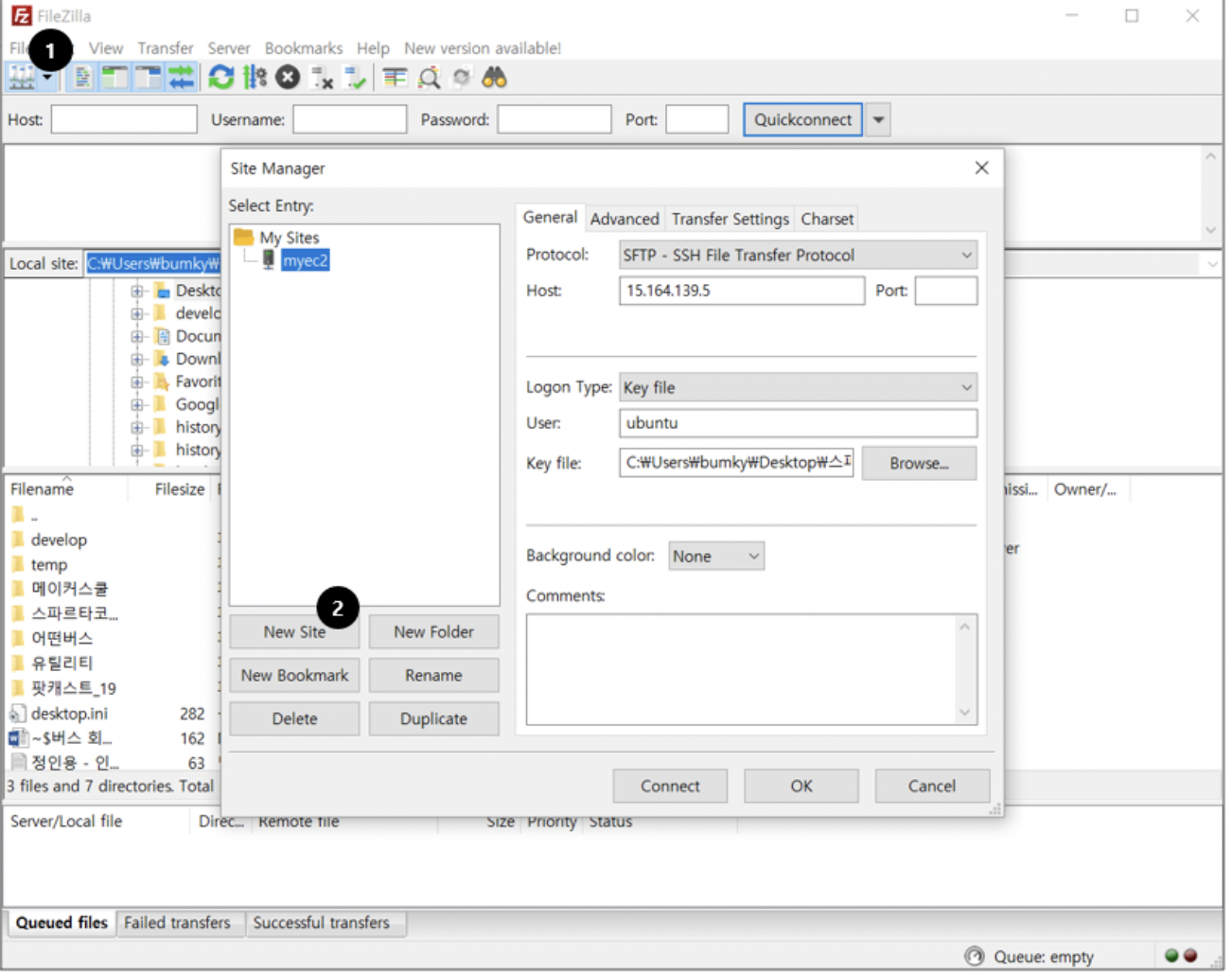
7. 이렇게 파일이 만들어진 것을 확인했으면 파이질라를 실행시킨다.
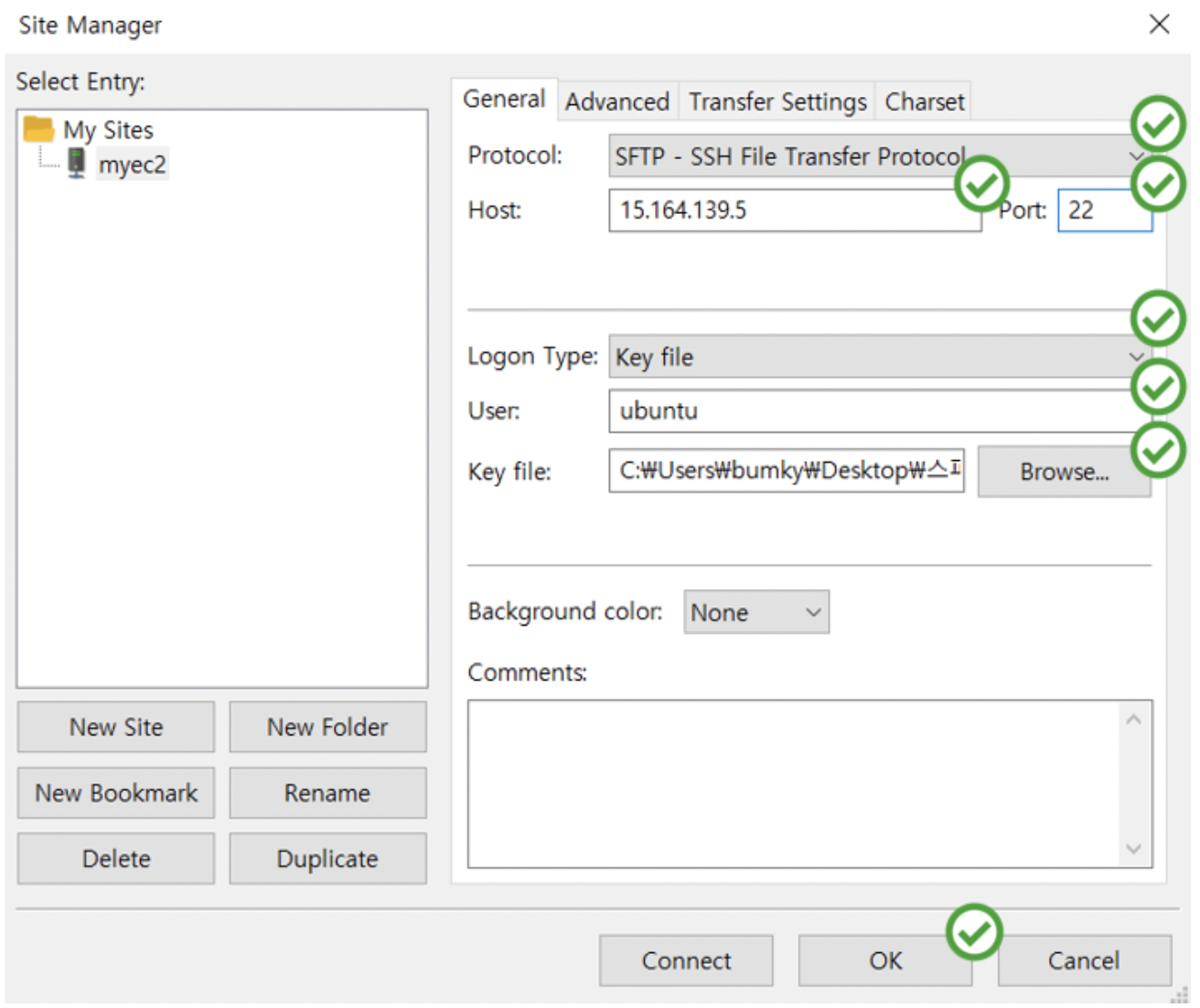
왼쪽 상단의 스크린 세계 모양 아이콘을 클릭하면 다음과 같은 창이 뜬다.
8. My Sites에 myec2라는 파일을 만들어 준 뒤, 다음과 같이 설정을 맞춰 준다. 참고로 Host에는 각자 AWS에 갖고 있는 아까도 복붙 하면서 사용했던 퍼플릭 아이피 주소를 넣어주면 된다.
9. 그렇게 하면 다음과 같은 창이 뜨는데, 왼쪽이 내 컴퓨터 오른쪽이 방금 내가 산 컴퓨터가 된다.
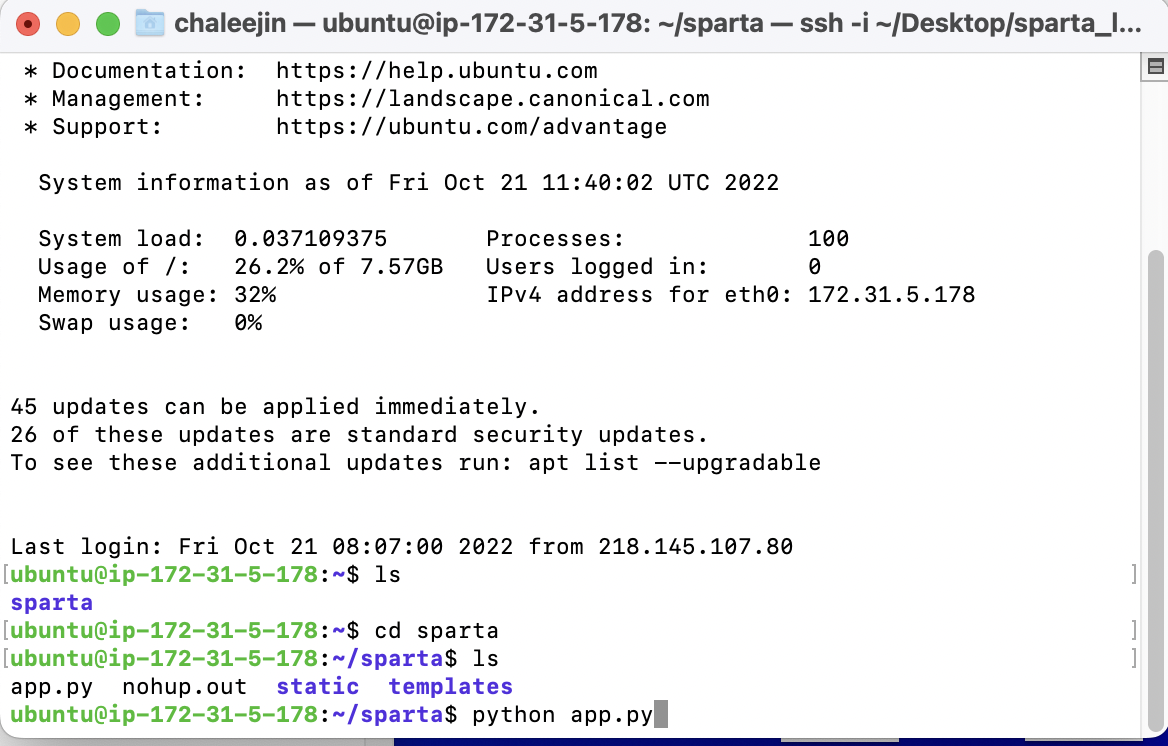
방금 터미널 창을 통해 만들어 두었던 스파르타 폴더에(오른쪽) 내가 올리고자 하는 웹페이지 소스인 static, templates, app.py를 드래그해서 옮겨준다.
10. 그다음 다시 터미널 창으로 돌아와 아래와 같은 순서로 입력!
- cd sparta (sparta 폴더로 들어감)
- ls (폴더 내용물을 보여줌)
- python app.py (만들어 뒀던 서버를 실행시켬줌)
- 그리고 마지막으로 스크린샷에는 없지만 nohup python app.py & 를 치고 엔터를 하면 배포가 완료된다.
※ 나의 페이지가 이미 배포가 되어있는 상태에서 정리하려다 보니 뭔가 과정이 깔끔하지 않은 점 양해 부탁드립니다!
11. 이 과정을 마무리하고 브라우저에 [http://내 AWS아이피/]를 입력하면 내가 만들어 두었던 웹페이지가 화면에 뜨는 것을 확인할 수 있다.
3) 도메인 연결하기
① 도메인 구입/연결
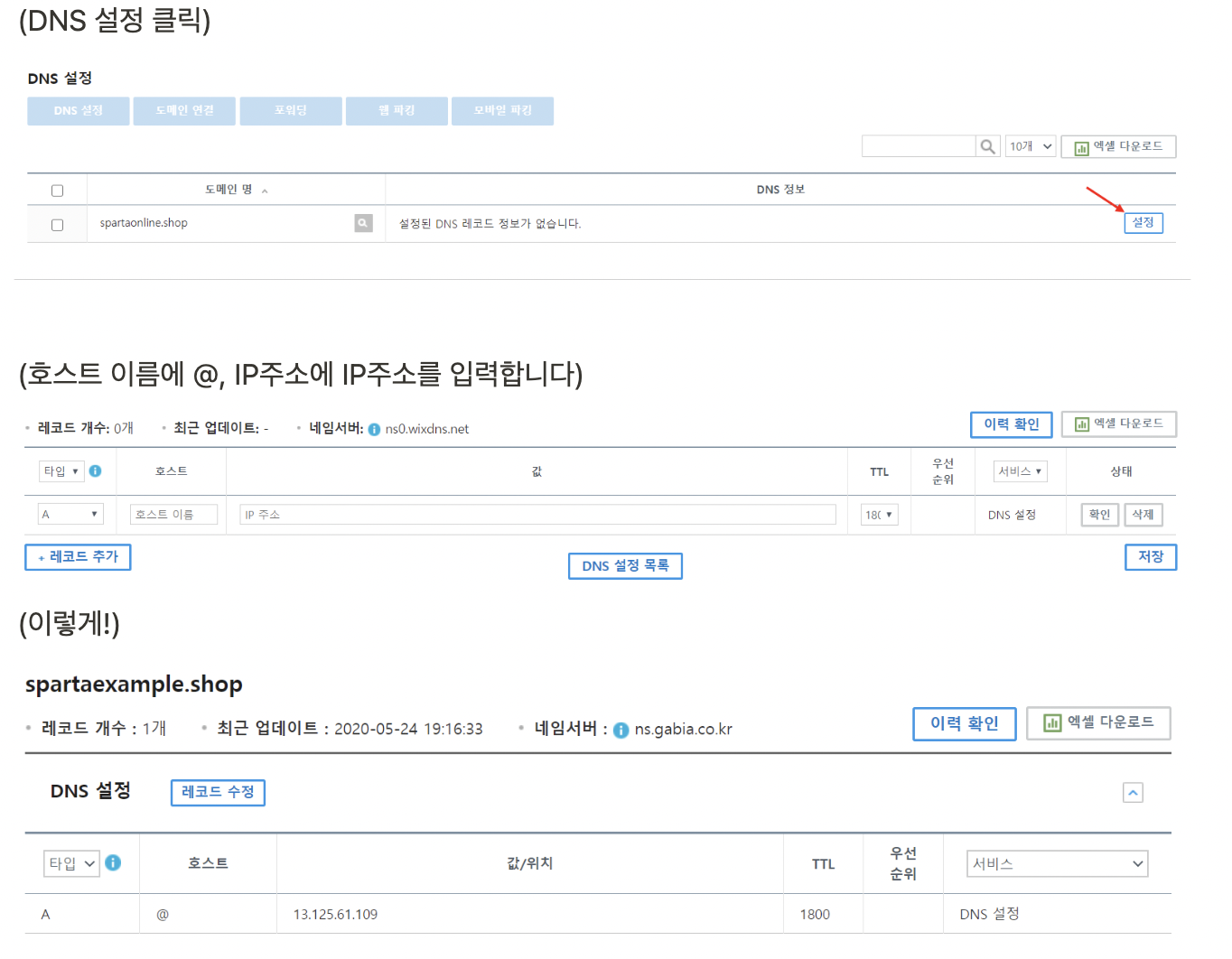
도메인을 구매한다는 것은 네임서버를 운영해주는 업체에 IP와 도메인 매칭 유지비를 내는 것.
가비아라는 사이트를 이용해 도메인을 구입해 놓았다.
가비아에서 내 아이피 주소에 원하는 도메인 이름을 설정해 준다.
4) 웹페이지 수정하고 다시 업로드하는 방법
※ 나는 이미 이전에 같은 도메인에 첫 과제로 만들었던 팬명록 페이지를 올려놓은 상태였기 때문에 다시 새로 만든 웹페이지를 업로드하는 과정이 가장 많이 헷갈렸다. 이 부분을 내가 이해한 방식대로 정리해 보자면!
1. 위에 정리해 둔 [2) 내 프로젝트 서버에 올리기 -②서버 세팅하기] 과정을 참고하여 1번부터 6번까지 실행시켜 sparta 폴더에 접속해 준다. 그다음 cd spart 엔터, 그 후 다시 python app.py 엔터 실행.
2. 여기가 중요하다! 실행시켜 놓았던 웹페이지를 잠시 꺼주는 역할을 하는 코드를 입력한다.
아 쉽지 않다 쉽지 않아! 리눅스 명령어를 입력하는 과정이 너무나 생소하고 헷갈리고 또 commend not found 등과 같은 다양한 에러를 구글링을 통해 해결하며 따라가야 했던 수업이다. 이 부분은 차라리 첫 강의를 수강했을 때 따라만 했기 때문에 오류가 없었는데, 만들어 놓았던 도메인에 똑같은 작업을 반복하려다 보니까 자꾸만 에러가 났던 것 같다.
아마도 제 3자의 눈으로 오늘 나의 포스트를 보자면 스킵되어있는 부분이 많아서 (스크린샷을 일일이 하지 못함 ㅠ) 이해하기 어렵게 느껴지실 것 같다. 일단 중요한 부분은 원래 만들었던 웹페이지를 내리고 수정하는 과정이라고 생각하는데, 리눅스 명령어를 잘 입력해서 원하는 폴더에 접근을 해주고, 삭제 코드를 입력해서 페이지를 내려주고, 파이질라에 다시 새로운 파일을 업데이트해주고, 다시 nohup코드로 페이지를 다시 배포해주는 이 과정! (헥헥) 그것을 잘 기억해 주면 될 것 같다.
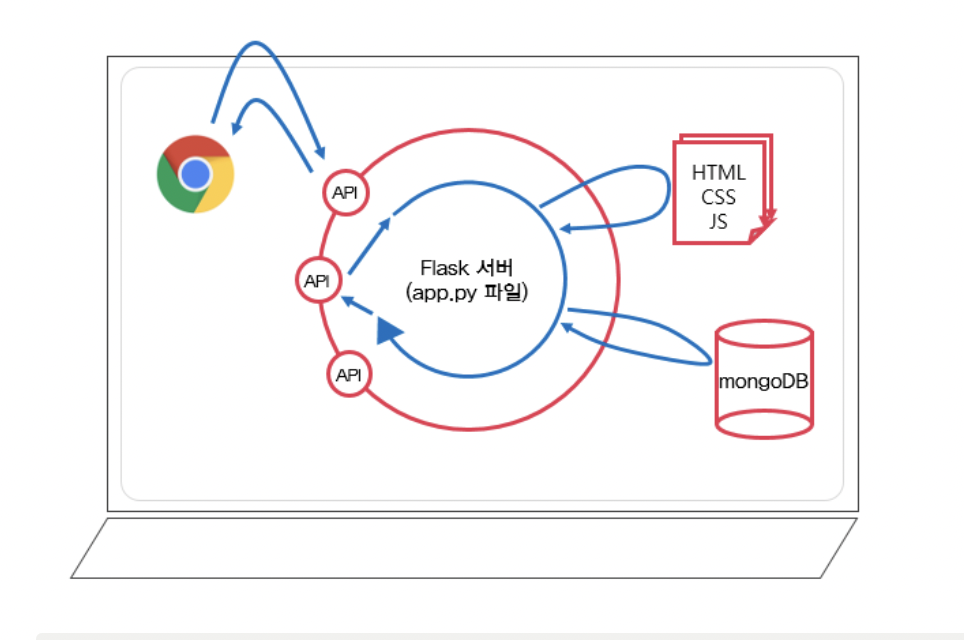
로컬 개발환경이란 같은 컴퓨터에다 서버도 만들고, 요청도 하는 방식. 즉, 클라이언트 = 서버가 되는 것!
클라우드 서비스를 이용하면 아래와 같은 그림이 될 수 있다.
출처 : 스파르타코딩클럽
Flask 프레임워크
서버를 구동시켜주는 편한 코드 모음. 서버를 구동하려면 필요한 복잡한 일들을 쉽게 가져다 쓸 수 있다.
파일 이름은 아무렇게나 해도 상관없지만, 통상적으로 flask 서버를 돌리는 파일은 app.py라고 이름 짓는다.
지난 글에 올린 것처럼 환경설정 → python interpreter에서 검색 후 패키지 설치하면 준비 완료!
Flask 기초
① @app.route('/) 부분을 수정해서 URL을 나눌 수 있다. 단, 주의할 점은 url 별로 함수명이 같거나, route('/') 내의 주소가 같으면 안 됨.
from flask import Flask
app = Flask(__name__)
@app.route('/')
def home():
return 'This is Home!'
@app.route('/mypage')
def mypage():
return 'This is My Page!'
if __name__ == '__main__':
app.run('0.0.0.0',port=5002,debug=True)
이렇게 한 후 오른쪽 마우스 클릭 → 실행 → 브라우저에서 localhost:5002/ 주소창으로 가면 웹페이지가 생성되는 것을 볼 수 있다.
② 기본 폴더구조
프로젝트 폴더 안에 static 폴더 (이미지, css파일을 넣어둡니다), templates 폴더 (html 파일을 넣어둡니다), app.py 파일 이렇게 세 개를 만들어두고 시작
왼쪽 프로젝트 아래부분 참고!
index.html 파일을 templates 안에 만들어 준 다음 flask 내장 함수 render_template를 이용해 html 파일을 불러줄 수 있음
from flask import Flask, render_template //이 라인에서 프레임워크 임포트를 확인 할 수 있다
app = Flask(__name__)
## URL 별로 함수명이 같거나,
## route('/') 등의 주소가 같으면 안됩니다.
@app.route('/')
def home():
return render_template('index.html')
if __name__ == '__main__':
app.run('0.0.0.0', port=5002, debug=True)
③ GET, POST 요청 타입
클라이언트는 요청할 때 HTTP request method(요청 메소드)라는 방식을 통해 어떤 요청 종류인지 응답하는 서버 쪽에 정보를 알려준다.
[GET 요청 방식]
통상적으로 데이터 조회(Read)를 요청할 때 → 영화 목록 조회
데이터 전달: URL 뒤에 물음표를 붙여 key=value로 전달 → 예: google.com?q=북극곰
확실히 강의를 3번째 듣다 보니까 예전에 강의를 따라서 치던 코드를 이젠 과제할 때 직접 쳐볼 수 있게 되었다. POST형식과 GET형식의 유기적인 구조를 조금은 더 이해할 수 있게 된 것 같다. 물론 아직 완벽하진 않지만, 한 번 더 수강을 한다면 더 이해가 쉬울 것 같은 느낌 ! 처음부터 완전히 이해를 하기보다 일단 반복해보고 그 과정을 통해 서서히 이해하는 것이 도움이 되는 것 같다. 그리고 오늘 과제를 하면서 계속해서 오류가 떴는데, 알고 보니 comment 스펠링이 하나 틀려서 발생했던 버그였다.
이젠 오류가 발생해도 오류 창의 메시지 첫 줄을 확인하는 습관이 생겼는데, 정확한 오류가 무엇인지는 몰라도 몇 번째 줄의 오류인지는 알 수 있어서 오류를 찾는 방법도 발전한 것 같다. 남들보다 느리지만 어제의 나보다 발전하고 있는 나를 칭찬하며 오늘 회고 끝.
(강의 회고를 하기 전에, 인터넷 검색을 통해 파이썬에 대한 설명을 좀 더 찾아 정리해 보았다.)
Python is a high-level, general-purpose programming language. Its design philosophy emphasizes code readability with the use of significant indentation. (Indentation = 들여쓰기)
파이썬은 네덜란드 개발자 귀도 반 로섬(GuidovanRossum)이 만든 언어
구글은 파이썬을 많이 사용하는 기업으로 알려져 있다. 구글 내부에서 사용하는 코드 리뷰 도구, ‘앱 엔진’ 같은 클라우드 제품 등이 파이썬을 이용해 만들어졌다.
파이썬은 문법이 간결하고 표현 구조가 인간의 사고 체계와 닮아 있다. 이 덕분에 초보자도 쉽게 배울 수 있고 다양한 분야에 활용할 수 있다는 장점이 있다. (JS보다 직관적 !)
반면 단점으로는 속도가 느리다는 평가도 있으며, 모바일 앱 개발 환경에서 사용하기 힘들다. 또한 컴파일 시 타입 검사가 이뤄지지 않아 개발자가 실수할 여지가 조금 더 많다거나 멀티코어를 활용하기 쉽지 않다는 지적도 있다.
[출처 : wikipedia] ,[출처 : 네이버 지식백과]
2) 파이썬 기초문법
① 변수 & 기본 연산
a = 3 # 3을 a에 넣는다
b = a # a를 b에 넣는다
a = a + 1 # a+1을 다시 a에 넣는다
num1 = a*b # a*b의 값을 num1이라는 변수에 넣는다
num2 = 99 # 99의 값을 num2이라는 변수에 넣는다
# 변수의 이름은 마음대로 지을 수 있음!
# 진짜 "마음대로" 짓는 게 좋을까? var1, var2 이렇게?
② 자료형
: 숫자, 문자형, 리스트 형 (Javascript의 배열형과 동일), Dictionary 형 (Javascript의 dictionary형과 동일), Dictionary 형과 List형의 조합형이 있다.
//숫자, 문자형
name = 'bob' # 변수에는 문자열이 들어갈 수도 있고,
num = 12 # 숫자가 들어갈 수도 있고,
is_number = True # True 또는 False -> "Boolean"형이 들어갈 수도 있습니다.
-------------------------------------------------------------------
//리스트 형 (Javascript의 배열형과 동일)
a_list = []
a_list.append(1) # 리스트에 값을 넣는다
a_list.append([2,3]) # 리스트에 [2,3]이라는 리스트를 다시 넣는다
# a_list의 값은? [1,[2,3]]
# a_list[0]의 값은? 1
# a_list[1]의 값은? [2,3]
# a_list[1][0]의 값은? 2
-------------------------------------------------------------------
//Dictionary 형 (Javascript의 dictionary형과 동일)
a_dict = {}
a_dict = {'name':'bob','age':21}
a_dict['height'] = 178
# a_dict의 값은? {'name':'bob','age':21, 'height':178}
# a_dict['name']의 값은? 'bob'
# a_dict['age']의 값은? 21
# a_dict['height']의 값은? 178
------------------------------------------------------------------
//Dictionary 형과 List형의 조합
people = [{'name':'bob','age':20},{'name':'carry','age':38}]
# people[0]['name']의 값은? 'bob'
# people[1]['name']의 값은? 'carry'
person = {'name':'john','age':7}
people.append(person)
# people의 값은? [{'name':'bob','age':20},{'name':'carry','age':38},{'name':'john','age':7}]
# people[2]['name']의 값은? 'john'
※ 자바스크립트에서 함수를 쓸 때 {}를 사용했다면, 파이썬은 들여 쓰기로 구분을 하기 때문에 들여 쓰기가 아주 중요하다!
④ 조건문 (if / else로 구성)
def oddeven(num): # oddeven이라는 이름의 함수를 정의한다. num을 변수로 받는다.
if num % 2 == 0: # num을 2로 나눈 나머지가 0이면
return True # True (참)을 반환한다.
else: # 아니면,
return False # False (거짓)을 반환한다.
result = oddeven(20)
# result의 값은 무엇일까요? True
⑤ 반복문 (무조건 리스트와 함께 쓰임, JS와 가장 다른 부분!)
fruits = ['사과','배','배','감','수박','귤','딸기','사과','배','수박']
count = 0
for fruit in fruits:
if fruit == '사과':
count += 1
print(count)
# 사과의 갯수를 세어 보여줍니다.
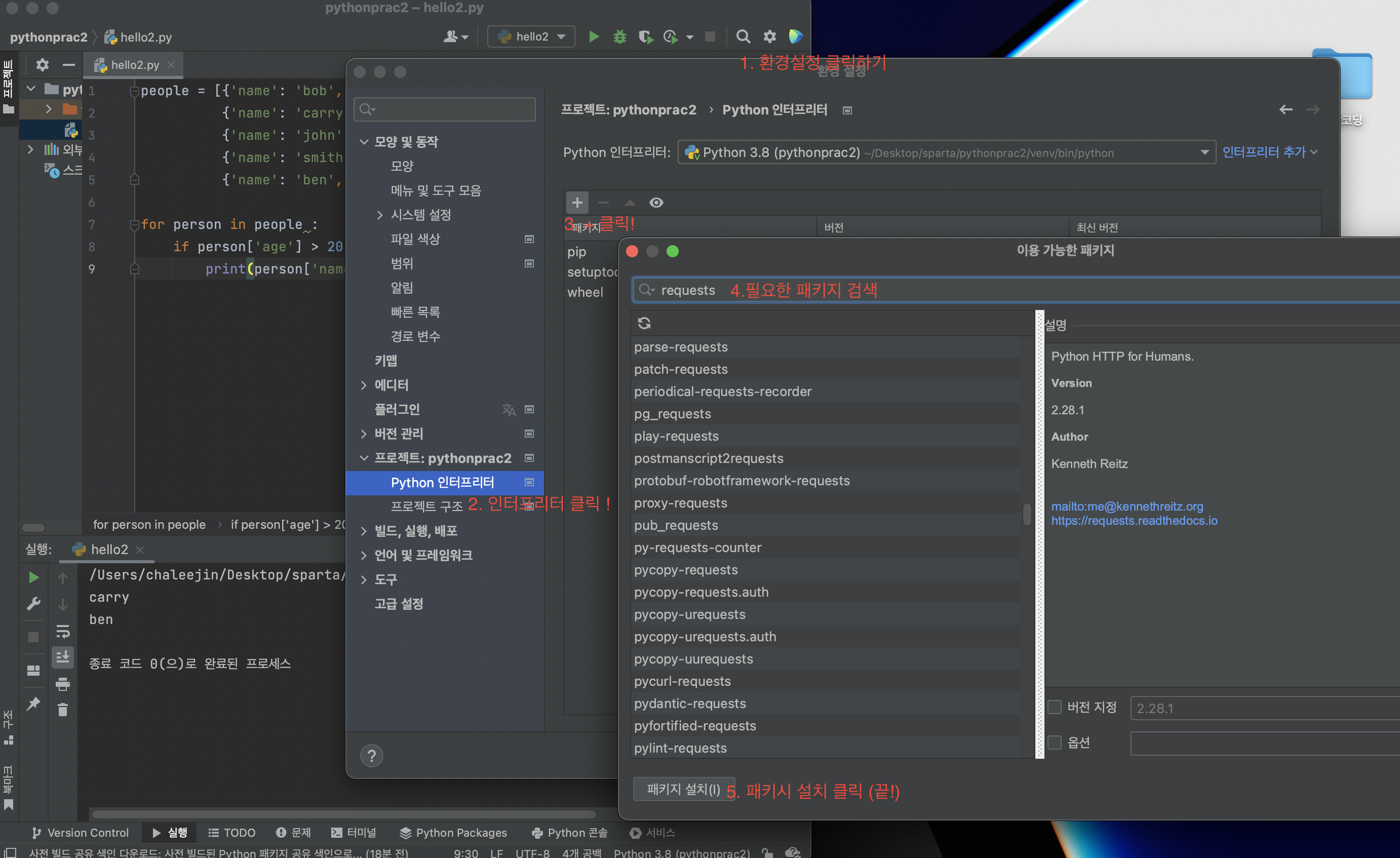
3) 파이썬에서 라이브러리 사용하는 법
참고로 파이썬파일을 만들 때 생성되는 venv( = 가상 환경 virtual environment) 파일은 필요한 라이브러리를 모아두는 곳이다.
이 남들이 만들어 놓은 라이브러리를 '패키지'라고 한다. 패키지 설치 방법은 다음과 같다. (패키지 설치 = 외부 라이브러리 설치)
빨간색 글씨 참조!
위는 파이썬을 통해 코드를 작성할 때 필요한 패키지들을 다운로드하는 방법이다. 빨간 글씨의 순서대로 실행해 주면 된다. 참고로 나는 맥북 프로 14를 사용하고 있는데 보안상의 문제 때문인지 항상 certifi라는 패키지를 추가로 설치해 주어야 다른 패키지들 import가 가능했다. 이번 강의에서는 requests, bs4(-> beautifulsoup4), pymonggo, dnspthon, certifi 패키지를 사용하였다. 아래 그림에서 가장 윗 윗 두줄을 참고하면 되겠다.
import requests # requests,bs4 라이브러리 설치 필요
from bs4 import BeautifulSoup
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨
# 이제 코딩을 통해 필요한 부분을 추출하면 된다.
soup = BeautifulSoup(data.text, 'html.parser')
#############################
# (입맛에 맞게 코딩)
#############################
4) 웹 스크래핑(크롤링) 기초
※ 크롤링은 두 가지 작업이 필요하다
① 요청해서 html 가져오기 ( → requests 라이브러리로 구현)
② 그안에서필요한정보찾기(타이틀,이미지등) → bs4 (BeautifulSoup) 라이브러리로 구현
③ headers 란? 우리가코드에서콜을날릴때마치브라우저에서콜을날리는것처럼하는것.
방법 ) 항상 정확하지는 않으나, 크롬 개발자 도구를 참고할 수 있다.
원하는 부분에서 마우스 오른쪽 클릭 → 검사
원하는 태그에서 마우스 오른쪽 클릭
Copy → Copy selector로 선택자를 복사할 수 있음
(예시)
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
#old_content > table > tbody > tr:nth-child(3) > td.title > div > a
#old_content > table > tbody > tr:nth-child(4) > td.title > div > a
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
a = movie.select_one('td.title > div > a')
if a is not None:
title = a.text
rank = movie.select_one('td:nth-child(1) > img')['alt']
star = movie.select_one('td.point').text
print(rank, title, star)
※ 태그 안의 텍스트를 찍고 싶을 땐 → 태그.text / 태그 안의 속성을 찍고 싶을 땐 → 태그['속성']
참고 ) beautifulsoup 내 select에 미리 정의된 다른 방법
# 선택자를 사용하는 방법 (copy selector)
soup.select('태그명')
soup.select('.클래스명')
soup.select('#아이디명')
soup.select('상위태그명 > 하위태그명 > 하위태그명')
soup.select('상위태그명.클래스명 > 하위태그명.클래스명')
# 태그와 속성값으로 찾는 방법
soup.select('태그명[속성="값"]')
# 한 개만 가져오고 싶은 경우
soup.select_one('위와 동일')
5) DB개괄
자료를 필요할 때 쉽게 찾기 위해 사용하는 프로그램의 일종
우리 눈에 보이진 않지만, 사실 DB에는 Index라는 순서로 데이터들이 정렬되어 있다.
크게 두 가지 종류가 있다 ( SQL , No-SQL)
RDBMS(SQL) : 행/열의 생김새가 정해진 엑셀에 데이터를 저장하는 것과 유사. 정형화되어 있는 만큼, 데이터의 일관성이나 / 분석에 용이. 따라서 주로 대기업에서 많이 사용 ex) MS-SQL, My-SQL 등
No-SQL : 딕셔너리 형태로 데이터를 저장해두는 DB. 고로 데이터 하나하나마다 같은 값들을 가질 필요가 없다. 자유로운 형태의 데이터 적재에 유리한 대신, 일관성이 부족할 수 있다. 따라서 주로 스타트업에서 많이 사용 ex) MongoDB
유저가 몰리거나 , DB를 백업해야 하거나, 모니터링 하기가 아주 용이하다는 이유로 요새는 Cloud 형태를 많이 사용! ex) mongoDB Atlas
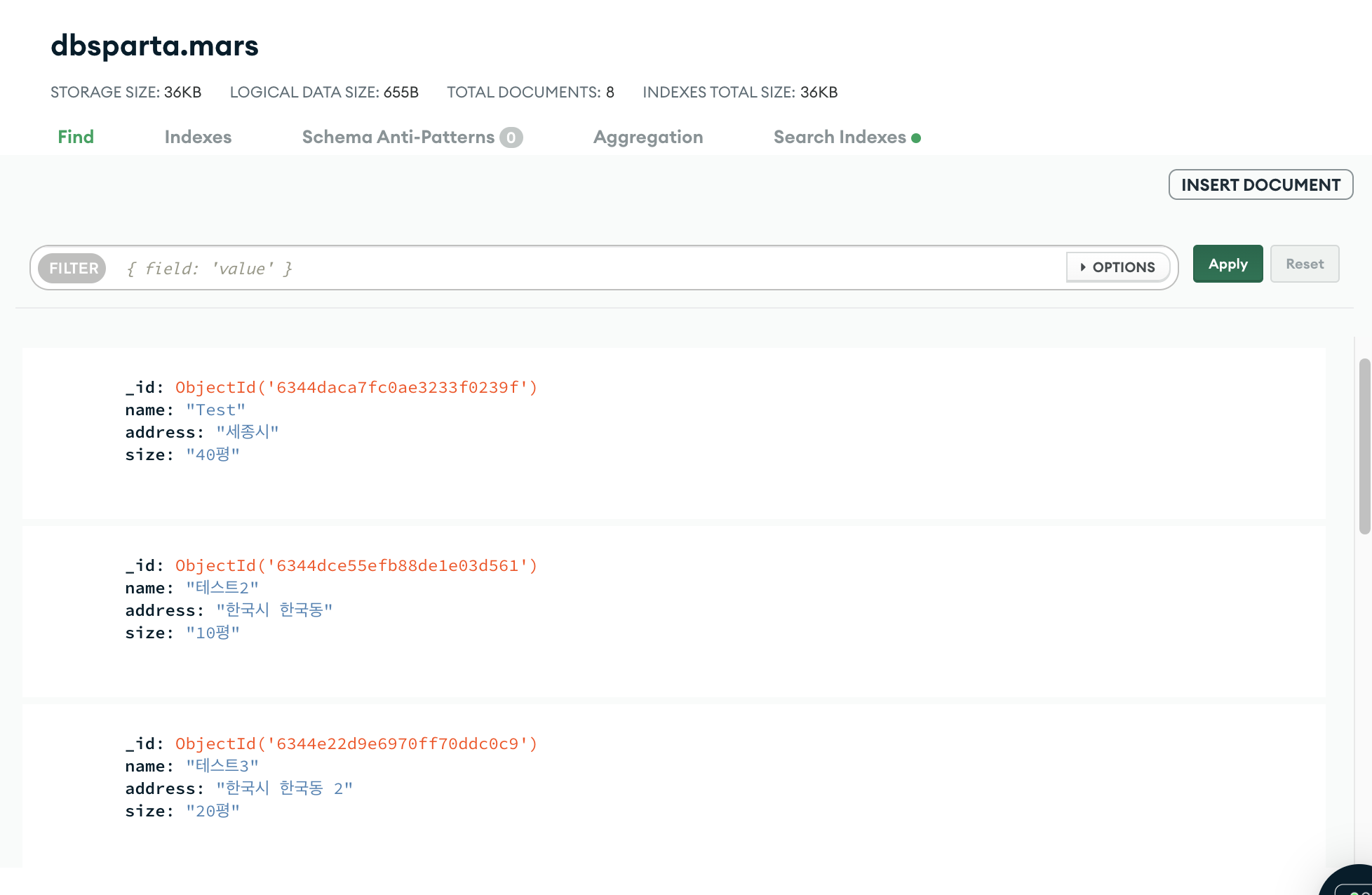
6) mongoDB
mongoDB 클라우스 서비스를 이용하면 쉽게 데이터를 불러오고 정리할 수 있다. 사용법은 구글링 해보기! 나는 이미 설치와 개설이 끝났기 때문에 나에게 필요한 정보만 기록하려 한다.
아래는 자주 사용하는 기본 코드! (필요할 때마다 복붙해서 사용하면 된다.)
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient('mongodb+srv://test:sparta@cluster0.sx4vg7k.mongodb.net/?retryWrites=true&w=majority',tlsCAFile=ca)
db = client.dbsparta
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
all_users = list(db.users.find({},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})
예시)
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient('mongodb+srv://test:sparta@cluster0.55vah.mongodb.net/Cluster0?retryWrites=true&w=majority')
db = client.dbsparta
# URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
soup = BeautifulSoup(data.text, 'html.parser')
# select를 이용해서, tr들을 불러오기
movies = soup.select('#old_content > table > tbody > tr')
# movies (tr들) 의 반복문을 돌리기
for movie in movies:
# movie 안에 a 가 있으면,
a_tag = movie.select_one('td.title > div > a')
if a_tag is not None:
rank = movie.select_one('td:nth-child(1) > img')['alt'] # img 태그의 alt 속성값을 가져오기
title = a_tag.text # a 태그 사이의 텍스트를 가져오기
star = movie.select_one('td.point').text # td 태그 사이의 텍스트를 가져오기
doc = {
'rank': rank,
'title': title,
'star': star
}
db.movies.insert_one(doc)
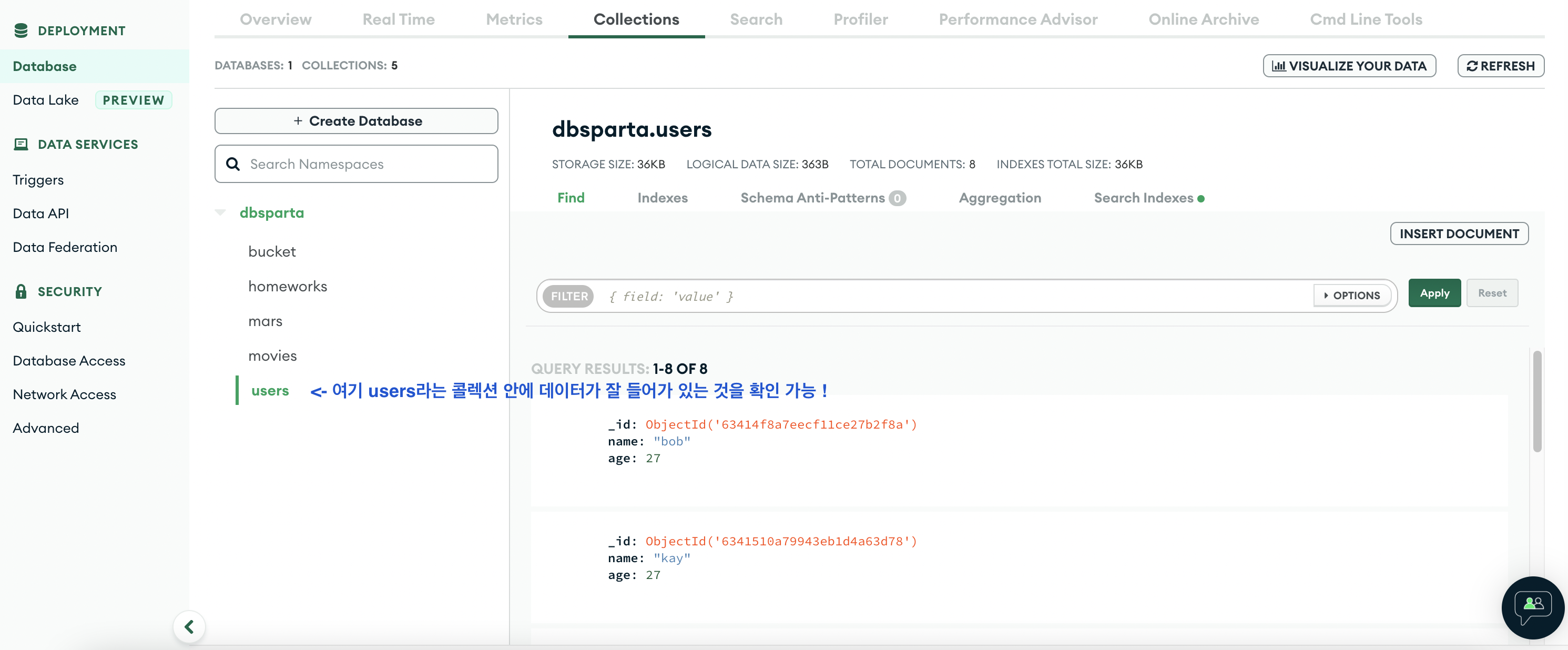
위 과정을 거치고 실행을 시키면 mongoDB의 movies 폴더에 크롤링한 데이터가 들어가 있음을 확인할 수 있다.
스파르타코딩클럽의 웹 개발 종합반은 개괄적인 내용을 다룬 강의이기 때문에 추가로 유튜브 채널 <생활코딩>에서 파이썬 강의를 들어보았다. 아직 극 초급단계인 내가 강의를 통해 이해한 포인트를 정리해보자면,
1. 파이썬은 프로그래밍 언어의 하나이다.
2. 자바스크립트와 다르게 들여 쓰기를 통해 함수를 구분하기 때문에 들여쓰기를 유의해야 한다.
3. 필요한 기능은 구글링을 통해 검색하여 사용한다. ex). text [0:2],. strip()
4. 매번 프로그래밍에 필요한 패키지들을 라이브러리에서 import 한 후 사용해야 한다.
5. 클라우드와 연결하게 되면 Open API에서 실시간으로 업데이트되는 데이터를 이용하여 필요한 코드를 작성하고 필요한 결과를 효율적으로 찾아낼 수 있다.
여기까지가 오늘의 이해인데, 잘하고 있는지는 모르겠다. 앞으로 실전 연습이나 프로젝트를 만들면서 지금의 추상적인 개념들을 구체화할 수 있을 것 같다. 모든 비전공자 코린이들 화잇팅!!