16. 복합 인덱스란 무엇인지 원리를 설명해주실 수 있을까요?
복합 인덱스란 두 개 이상의 컬럼을 합쳐서 인덱스를 만드는 것을 말합니다. 주로 단일 컬럼으로는 나쁜 분포도를 가지지만 여러 개의 컬럼을 합친다면 좋은 분포도를 가지고, Where절에서 AND 조건에 많이 사용되는 컬럼들을 복합 인덱스로 구성합니다. index Table에서 where에 포함된 값을 찾아옵니다. 해당 값의 table_id[PK]을 가져옵니다. 가져온 table_id [PK] 값으로 원본 테이블에서 값을 조회해옵니다.
17. 트랜잭션이란 무엇이고 원자성, 일관성, 고립성, 지속성이란 무엇인지 설명해주실 수 있을까요?
트랜잭션(Transaction 이하 트랜잭션)이란, 데이터베이스의 상태를 변화시키기 해서 수행하는 작업의 단위를 뜻한다. 데이터베이스의 상태를 변화시킨다는 것은 간단하게 말해서 질의어(SQL : SELECT, INSERT, DELETE, UPDATE)를 이용하여 데이터베이스를 접근 하는 것을 의미한다. 작업의 단위는 질의어 한문장이 아니고, 많은 질의어 명령문들을 사람이 정하는 기준에 따라 정하는 것을 의미한다.
- 원자성은 트랜잭션이 데이터베이스에 모두 반영되던가, 아니면 전혀 반영되지 않아야 한다는 것이다.
- 일관성은 트랜잭션의 작업 처리 결과가 항상 일관성이 있어야 한다는 것이다.
- 고립성은 둘 이상의 트랜잭션이 동시에 실행되고 있을 경우 어떤 하나의 트랜잭션이라도, 다른 트랜잭션의 연산에 끼어들 수 없다는 점을 가리킨다.
- 지속성은 트랜잭션이 성공적으로 완료됬을 경우, 결과는 영구적으로 반영되어야 한다는 점이다.
18. 정규화란 무엇이고 대표적인 장점과 단점은 무엇이 있을까요?
정규화의 기본 목표는 테이블 간에 중복된 데이터를 허용하지 않는다는 것입니다. 중복된 데이터를 허용하지 않음으로서 무결성을 유지할 수 있으며, DB의 저장 용량 역시 줄일 수 있습니다. 종속성 삭제로 데이터의 일관성과 무결성을 보장합니다. 릴레이션에서 발생 가능한 이상현상을 제거합니다. 정규화의 단점은 빈번한 join 연산 증가로 인한 시스템 실행과다 및 비효율적 검색 시간 이 있으며 과다한 검색 조건문 발생으로 부자연스러운 데이터베이스 semantics 초래가 우려됩니다.
19. HTTP에 비해 HTTPS가 더 안전한 원리를 설명해주실 수 있을까요?
HTTP란 서버/클라이언트 모델을 따라 데이터를 주고 받기 위한 프로토콜입니다. 이 HTTP에는 3가지 문제가 있습니다. 첫 번째 HTTP 는 평문 통신이기 때문에 도청이 가능하다. 두 번째 통신 상대를 확인하지 않기 때문에 위장이 가능하다. 세 번째 완전성을 증명할 수 없기 때문에 변조가 가능하다. 이 3가지 문제를 해결하기 위해 HTTPS는 SSL(Secure Socket Layer) or TLS(Transport Layer Security)와 같은 프로토콜을 사용하여 공개키/개인키 기반으로 데이터를 암호화하고 있습니다. 데이터는 암호화되어 전송되기 때문에 임의의 사용자가 데이터를 조회하여도 원본의 데이터를 보는 것은 불가능하고, 완정성 또한 증명할 수 있습니다.
20. TCP 3 way handshake란 무엇인지 설명해주실 수 있을까요?
TCP 3 way handshake란 연결하고자 하는 두 장치 간의 논리적 접속을 성립하기 위해 사용하는 연결 확인 방식으로, 3번의 확인 과정을 거친다고 해서 3 way handshake라고 부릅니다. 동작 과정은
1. SYN (synchronize sequence numbers) 연결 확인을 위해 보내는 무작위의 숫자값으로 클라이언트에서 서버로 보내고
2. ACK (acknowledgements) Client 혹은 Server로부터 받은 SYN에 1을 더해 SYN을 잘 받았다는 ACK와 SYN을 같이 보냅니다.
3. ACK (acknowledgements)를 보내 연결을 확인합니다.
21. TCP 와 UDP 를 비교하여 설명해주실 수 있을까요?
TCP는 연속성보다 신뢰성 있는 전송이 중요할 때에 사용되는 프로토콜이며,UDP는 TCP보다 빠르고 네트워크 부하가 적다는 장점이 있지만 신뢰성 있는 데이터 전송을 보장하지는 않습니다.그렇기 때문에 신뢰성보다는 연속성이 중요한 실시간 스트리밍과 같은 서비스에 자주 사용됩니다.
TCP는 Transmission Control Protocol의 약자이고, UDP는 User Datagram Protocol의 약자입니다. 두 프로토콜은 모두 패킷을 한 컴퓨터에서 다른 컴퓨터로 전달해주는 IP 프로토콜을 기반으로 구현되어 있고, 데이터 오류 검사를 위한 체크섬이 존재하지만, 서로 다른 특징을 가지고 있습니다. 신뢰성이 요구되는 애플리케이션에서는 TCP를 사용하고 간단한 데이터를 빠른 속도로 전송하고자 하는 애플리케이션에서는 UDP를 사용합니다. 또한 연결이 성공해야만 통신이 가능한 TCP와는 달리 연결 없이 UDP는 연결 없이 통신이 가능합니다.
22. Base64 인코딩이란 무엇인가요?
Base64 인코딩은 바이너리 데이터를 공통 ASCII 영역의 문자(TEXT)로만 이루어지는 문자열로 바꾸는 Encoding 방식입니다. 바이너리 데이터를 6Bit씩 자른 뒤 6Bit에 해당하는 문자를 Base64 색인표에서 찾아서 치환하는 방식으로 인코딩 합니다.
Base 64란 8비트 이진 데이터를 문자 코드에 영향을 받지 않는 공통 ASCII 영역의 문자들로만 이루어진 일련의 문자열로 바꾸는 인코딩 방식을 가리키는 개념이다.
23. 프로세스와 스레드를 비교하여 설명해주실 수 있을까요?
프로세스는 운영체제로부터 자원을 할당받은 작업의 단위입니다. 스레드는 프로세스가 할당받은 자원을 이용하는 실행 흐름의 단위입니다. 둘이 가장 큰 차이는 프로세스는 메모리에 올라갈 때 운영체제로부터 시스템 자원을 할당받는데 운영체제는 프로세스마다 각각 독립된 메모리 영역을, Code/Data/Stack/Heap의 형식으로 할당해준다. 그러나 스레드는 프로세스가 할당받은 메모리 영역 내에서 Stack 형식으로 할당된 메모리 영역은 따로 할당받고, 나머지 Code/Data/Heap 형식으로 할당된 메모리 영역을 공유한다. 따라서 각각의 스레드는 별도의 스택을 가지고 있지만 힙 메로리는 서로 읽고 쓸 수 있게 됩니다. 만약 한 프로세스가 실행하다가 오류가 발생하면 프로세스가 강제종료된다면 다른 프로세스에는 영향을 주지 않지만 스레드는 오류로 종료가 된다면 메모리 영역을 공유하고있는 스레드 모두 강제로 종료된다는 중요한 차이점이 존재합니다.
24. 동기와 비동기를 비교하여 설명해주실 수 있을까요?
동기는 데이터의 요청과 결과가 한 자리에서 동시에 일어나는것을 말합니다. 사용자가 데이터를 서버에게 요청한다면 그 서버가 데이터 요청에 따른 응답을 사용자에게 다시 리턴해주기 전까지 사용자는 다른 활동을 할 수 없으며 기다려야만합니다. 비동기는 동시에 일어나지 않는다는 의미입니다. 서버에게 데이터를 요청한 후 요청에 따른 응답을 계속 기다리지 않아도되며 다른 외부 활동을 수행하여도되고 서버에게 다른 요청사항을 보내도 상관없습니다.
25. 동시성과 병렬성을 비교하여 설명해주실 수 있을까요?
동시성은 적어도 두 개의 스레드가 진행 중일 때 존재하는 조건이며, 가상 병렬 처리의 한 형태로 시간 분할(time-slicing)을 포함합니다. 우리가 흔히 ‘동시’라고 이야기 하지만 컴퓨터(코어)는 한번에 하나의 명령어만 처리할 수 있다. 즉, 두개 이상의 알고리즘이 하나의 코어내에서 스레드간에 빠르게 교차되면서 실행되기 때문에 ‘동시’라고 느끼는 것입니다. 병렬성을 이야기하려면 적어도 2개 이상의 코어가 있어야 합니다. 병렬성도 동시성을 의미하지만 동시성과의 차이는 각 코어내의 스레드가 실제로 동시에 명령어를 실행할 수 있음을 말합니다. 그러므로 두개의 알고리즘이 정확히 같은 시점에 실행될 때 이를 병렬적이라고 말할 수 있습니다.
26. JVM 이란 무엇이고 왜 필요한지 설명해주실 수 있을까요?
JVM이란 Java Virtual Machine 의 줄임말로, Java Byte Code 를 운영체제에 맞게 해석해주는 역할을 한다. 즉, 작성한 자바 프로그램의 실행 환경을 제공하는 자바 프로그램의 구동 엔진이다. Java compiler 는 .java 파일을 .class 라는 자바 바이트코드로 변환시켜주는데 Byte Code 는 기계어(Native Code)가 아니므로 OS 에서 바로 실행이 되지 않는다. 이때 JVM은 OS가 Byte Code 를 이해할 수 있도록 해석해주는 역할을 담당한다. JVM은 메모리 관리도 담당한다. 이를 '가비지 컬렉터'라고 하는데, 가비지 컬렉터는 Java7부터 힙 영역의 객체들을 관리하는 역할을 담당한다.
27. Java가 컴파일되는 과정은 어떻게 되는지 설명해주실 수 있을까요?
1. 개발자가 자바 소스코드(.java)를 작성한다.
2. 자바 컴파일러가 자바 소스코드(.java)파일을 읽어 바이트코드(.class)로 컴파일 한다. 바이트코드(.class)파일은 아직 컴퓨터가 읽을 수 없는 JVM(자바 가상 머신)이 읽을 수 있는 코드이다. (java - > class)
3. 컴파일된 바이트코드(.class)를 JVM의 클래스로더(Class Loader)에게 전달한다.
4. 클래스 로더는 동적로딩(Dynamic Loading)을 통해 필요한 클래스들을 로딩 및 링크하여 런타임 데이터 영역 (Runtime Data Area), 즉 JVM의 메모리에 올린다.
5. 실행엔진(Execution Engine)은 JVM 메모리에 올라온 바이트 코드들을 명령어 단위로 하나씩 가져와서 실행한다. 이 때 실행 엔진은 두 가지 방식(인터프리터와 JIT컴파일러)로 변경한다.
28. JVM의 스택과 힙메모리 영역에 대해 아는 만큼 설명해주실 수 있을까요?
Stack의 경우에는 정적으로 할당된 메모리 영역이다. Stack에서는 Primitive 타입 (boolean, char, short, int, long, float, double) 의 데이터가 값이랑 같이할당이 되고, 또 Heap 영역에 생성된 Object 타입의 데이터의 참조 값이 할당 된다. 그리고 Stack 의 메모리는 Thread당 하나씩 할당 된다. 만약 새로운 스레드가 생성되면 해당 스레드에 대한 Stack이 새롭게 생성되고, 각 스레드 끼리는 Stack 영역을 접근할 수 가 없다. Heap의 경우에는 동적으로 할당된 메모리 영역이다. 힙 영역에서는 모든 Object 타입의 데이터가 할당이 된다. (참고로 모든 객체는 Object 타입을 상속받는다.) Heap 영역의 Object를 가리키는 참조변수가 Stack에 할당이 된다. 어플리케이션에서의 모든 메모리 중에서 Stack에 쌓이는 애들 빼고는 전부 이 Heap 쌓인다고 보면 된다.
자바의 메모리 구조는 메소드영역, 스택영역, 힙영역으로 구성된다.
- 메소드(Method) 영역 : Static 영역이라고도 하며 전역 변수와 정적 멤버변수(static 변수)가 저장되는 영역이다.
- 스택(Stack) 영역 : 지역변수, 인자값, 리턴값이 저장되는 영역이고 메소드 안에서 사용되는 기본형 변수들이 값과 함께 저장되고 Heap 영역에 생성된 객체들을 참조하는 주소값이 할당된다.
- 힙(Heap) 영역 : 자바 프로그램에서 사용되는 모든 인스턴스 변수(객체)들이 저장되는 영역이며 자바에서는 new를 사용하여 객체를 생성하면 힙 영역에 저장된다. 힙 영역은 메모리 공간이 동적으로 할당되고 해제되며 메모리의 낮은 주소에서부터 높은 주소로 할당이 이루어진다.
29. 클래스와 인스턴스의 차이에 대해 설명해주실 수 있을까요?
클래스는 객체를 만들어 내기 위한 설계도 혹은 틀이라고 할 수 있으며, 연관되어 있는 변수와 메서드의 집합입니다. 인스턴스는 클래스를 바탕으로 구현된 구체적인 실체이며, 하나의 클래스를 통해서 다양한 인스턴스들을 만들 수 있습니다. 다양한 인스턴스가 만들어진다한들, 서로 다른 행동을 할 수 있게되니 재활용성을 더욱 높일 수 있습니다.
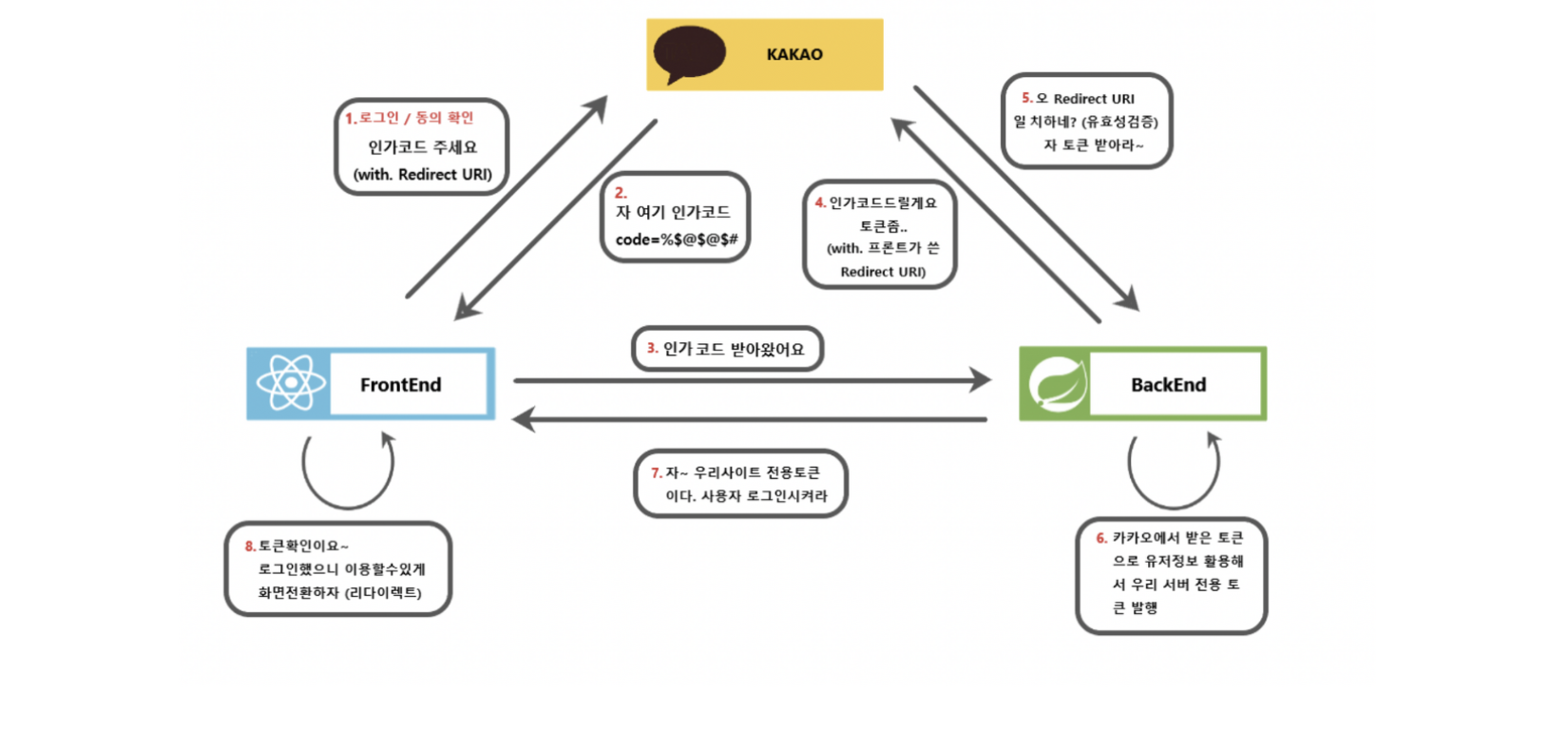
30. Spring Security의 구조와 JWT 발급 과정에 대해 설명해주실 수 있을까요?
Spring Security란 Spring 기반의 어플리케이션의 보안(인증과 권한, 인가 등)을 담당하는 스프링 하위 프레임워크 입니다. Spring Security는 '인증'과 '권한'에 대한 부분을 Filter 흐름에 따라 처리 하고 있습니다. Filter는 Dispatcher Servlet으로 가기 전에 적용되므로 가장 먼저 URL 요청을 받지만, Interceptor는 Dispatcher와 Controller 사이에 위치한다는 점에서 적용 시기의 차이가 있습니다. JWT가 발행되면, 발급된 JWT의 구성은 header에는 토큰타입,해시 암호화 알고리즘을 담고 Paylaod는 토큰의 정보를 담 고, Signature에는 시크릿 키를 담습니다. 사용자가 요청에 JWT를 보내면 서버에서 시크릿키 만을 활용해서 JWT 토큰의 유효성을 체크하고, 유효한 토큰이라면 사용자인증을 거칩니다. 이후 토큰의 만료기간을 체크하고, 토큰의 권한을 체크 합니다.
Spring Security의 대표적인 보안 구성으로는 인증(Authentication)과 인가(Authorization)를 들 수 있다. 이 인증과 인가를 위해 Principal을 아이디로, Credential을 비밀번호로 사용하는 Credential 기반의 인증 방식을 사용한다. 이러한 이유로 Spring Security는 대부분의 유저 정보와 인증 인가를 위한 정보를 얻어내기 위한 인터페이스 명세와 그 구현체를 미리 정의해놓고 사용할 수 있도록 정의해 놓았고 우리는 사용하기만 하면 된다. 또한 http 요청 사이에 처리해야 하는 인증처리를 위해 스프링은 필터를 구현하고 있는데, JWT 토큰 방식을 사용하기 위해선 해당 필터 앞단에서 JWT 토큰의 생성과 발급이 위치하도록 해야하고, 반드시 Spring Security의 인증시스템에 등에 JWT로 인증한 사용자의 정보를 포함시켜야 한다. 이 인증 및 인가 사용자 정보는 SecurityContextHolder에 위치한다.